2 min read
How Beam AI Scaled from 50 to 5,000 Tasks per Minute – Without Breaking Things


Category
Agentic Automation
Share the article
Scaling an automation-heavy AI platform is never just about throwing more servers at the problem. It’s about rethinking infrastructure, optimizing execution, and designing for resilience. At Beam AI, we faced serious growing pains early on—our background tasks were consuming excessive resources, and we hit bottlenecks that made scaling a challenge.
Today, we run over 5,000 tasks per minute without breaking a sweat. Here’s how we engineered our way there.
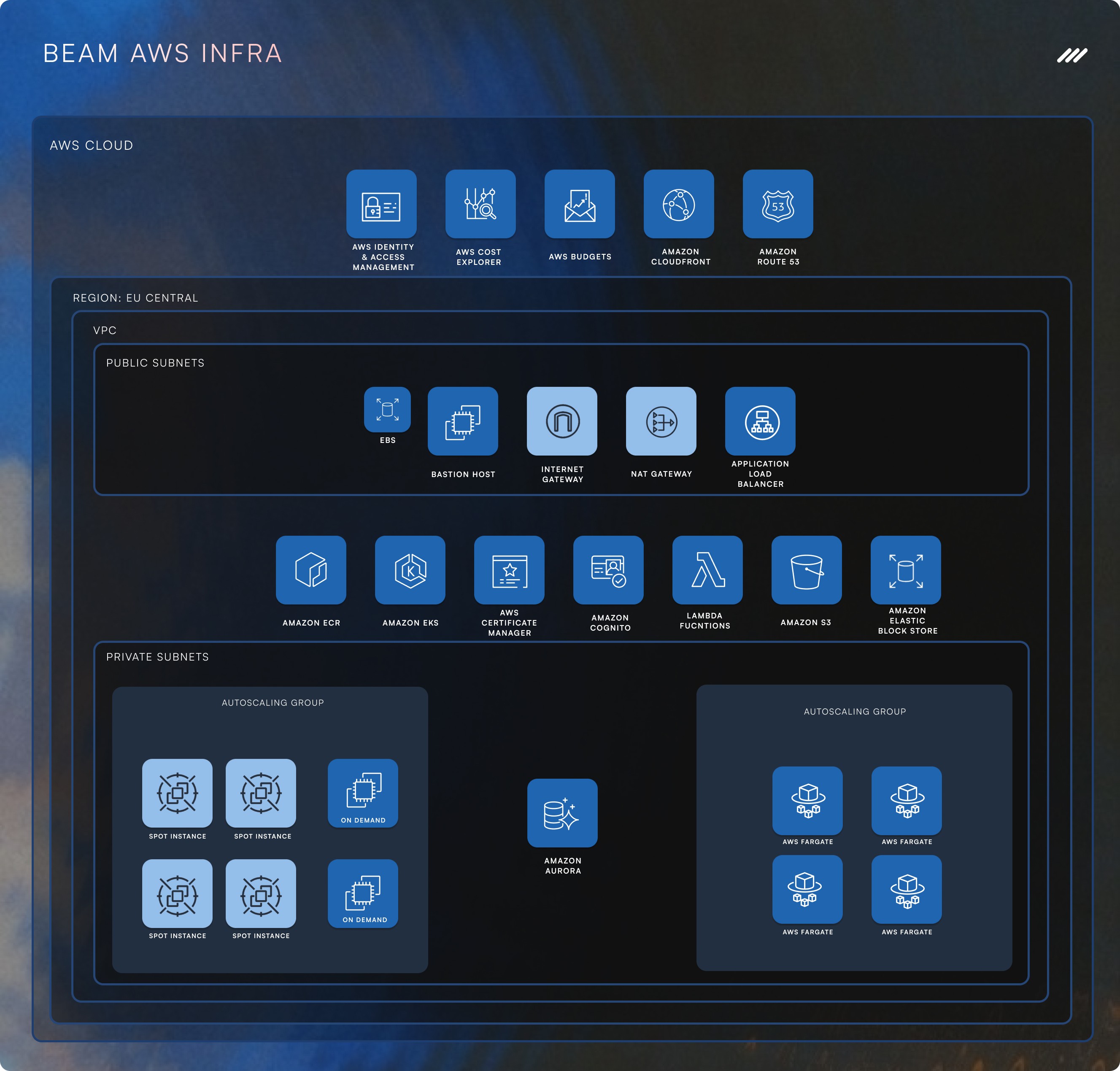
The Early Struggles - Why Our First System Couldn’t Scale
Beam AI’s backend processes vast amounts of data, running background tasks that automate workflows and execute AI-driven operations. But in the early days, our architecture was far from scalable:
Services were resource-hungry, limiting how many tasks we could process.
We relied on internal HTTP calls, leading to inefficiencies and potential failures.
Our system lacked fault tolerance, meaning one failure could take down an entire workflow.
It was clear we needed a radical overhaul.
Step 1: Kubernetes: The Backbone of Our Scalability
Our first major shift was moving to Kubernetes, which gave us:
→ High Availability: Ensuring services stayed up even if individual components failed.
→ Zero-Downtime Deployments: We could push updates without disrupting operations.
→ Fault Isolation: A single failing service wouldn’t impact the entire system.
By orchestrating our workloads with Kubernetes, we eliminated a major bottleneck and laid a scalable foundation for growth.
Step 2: Message Brokers: Replacing Synchronous Calls with Smart Queuing
Originally, Beam AI’s services communicated through direct HTTP calls, which created tight dependencies and single points of failure. The fix? A message broker.
With a message-driven architecture, we gained:
→ Asynchronous Processing: Services listen for messages instead of waiting on direct responses.
→ Load Management: We can limit how many tasks each service processes at a time.
→ Task Recovery: If a service crashes, it picks up right where it left off once it restarts.
This change transformed our efficiency, allowing services to communicate without blocking each other or overloading.
Step 3: Runtime Model Switching: Making AI More Cost-Efficient
AI models are powerful, but blindly using large models for every task is a cost and performance nightmare. We designed a dynamic model switching system that:
→ Chooses LLMs based on document length and complexity.
→ Uses different models for different document types to optimize speed and accuracy.
→ Reduces rate limits and API costs by using the right model for the right job.
This approach not only boosted performance but also made our system more cost-effective without sacrificing quality.
Step 4: Breaking Down Tasks for Maximum Reliability
Scaling isn’t just about doing more, it’s about doing more while staying resilient. We broke monolithic task execution into independent steps, so:
→ Each stage reports progress to the message broker.
→ Failed tasks can restart from the last completed step rather than starting over.
→ Parallel execution is possible, improving efficiency.
This gave us fine-grained control over automation workflows, making Beam AI more reliable than ever.
Step 5: Database Optimization: Moving to PostgreSQL with Vector Support
Handling vast amounts of structured and unstructured data required a rethink of our storage strategy. Initially, we used a mix of vector databases, but we transitioned to PostgreSQL with vector support for:
→ Faster lookups and retrieval of embeddings for AI models.
→ Centralized storage, reducing database fragmentation.
→ Better indexing for context-aware automation.
This move simplified our architecture without sacrificing performance.
Step 6: Custom API Executor: Automating External Calls for Agents
To improve how our AI agents interact with external APIs, we built a custom API executor that:
→ Handles API requests efficiently without blocking workflows.
→ Manages retries and failures to ensure reliability.
→ Integrates seamlessly into our automation stack.
This ensured smooth interactions between Beam AI and external services, making our automation more seamless and robust.

The Impact: From 50 Tasks to 5,000+ Tasks Per Minute
With these architectural changes, Beam AI experienced a massive leap in scalability. We went from processing fewer than 50 tasks at a time to handling over 5,000 tasks per minute—a 100x increase in capacity.
LLMOps: The Secret to Scalable AI Automation
Scaling AI-powered workflows requires more than just infrastructure upgrades, it demands LLMOps best practices to manage:
Performance tuning for optimal accuracy and speed.
Scalability frameworks that handle increasing demand.
Risk reduction via monitoring, disaster recovery, and security best practices.
Efficiency improvements through automation and intelligent resource allocation.
At Beam AI, LLMOps is at the core of our scaling strategy, allowing us to handle AI workflows efficiently, cost-effectively, and without performance trade-offs.
The Takeaway: Scaling is a Continuous Process
Scaling isn’t a one-time event, it’s an ongoing process of identifying bottlenecks, optimizing infrastructure, and leveraging the right technologies. By embracing Kubernetes, message brokers, dynamic model switching, and optimized databases, we built a system that can handle high-volume automation with stability and efficiency.
At Beam AI, we’re constantly iterating on our architecture to stay ahead. If you’re tackling similar scaling challenges, the key takeaway is simple: Design for resilience, automate intelligently, and always be ready to adapt.




