2 Min. Lesezeit
Wie Beam AI von 50 auf 5.000 Aufgaben pro Minute skalierte – ohne dabei Dinge zu zerstören


Kategorie
Agentische Automatisierung
Artikel teilen
Die Skalierung einer automatisierungsintensiven AI-Plattform ist nicht einfach nur eine Frage von mehr Servern. Es geht darum, die Infrastruktur neu zu überdenken, die Ausführung zu optimieren und auf Belastbarkeit zu gestalten. Bei Beam AI hatten wir früh ernsthafte Wachstumsschmerzen — unsere Hintergrundaufgaben verbrauchten übermäßige Ressourcen, und wir stießen auf Engpässe, die das Skalieren zu einer Herausforderung machten.
Heute führen wir über 5.000 Aufgaben pro Minute aus, ohne ins Schwitzen zu geraten. So haben wir unseren Weg dorthin konstruiert.
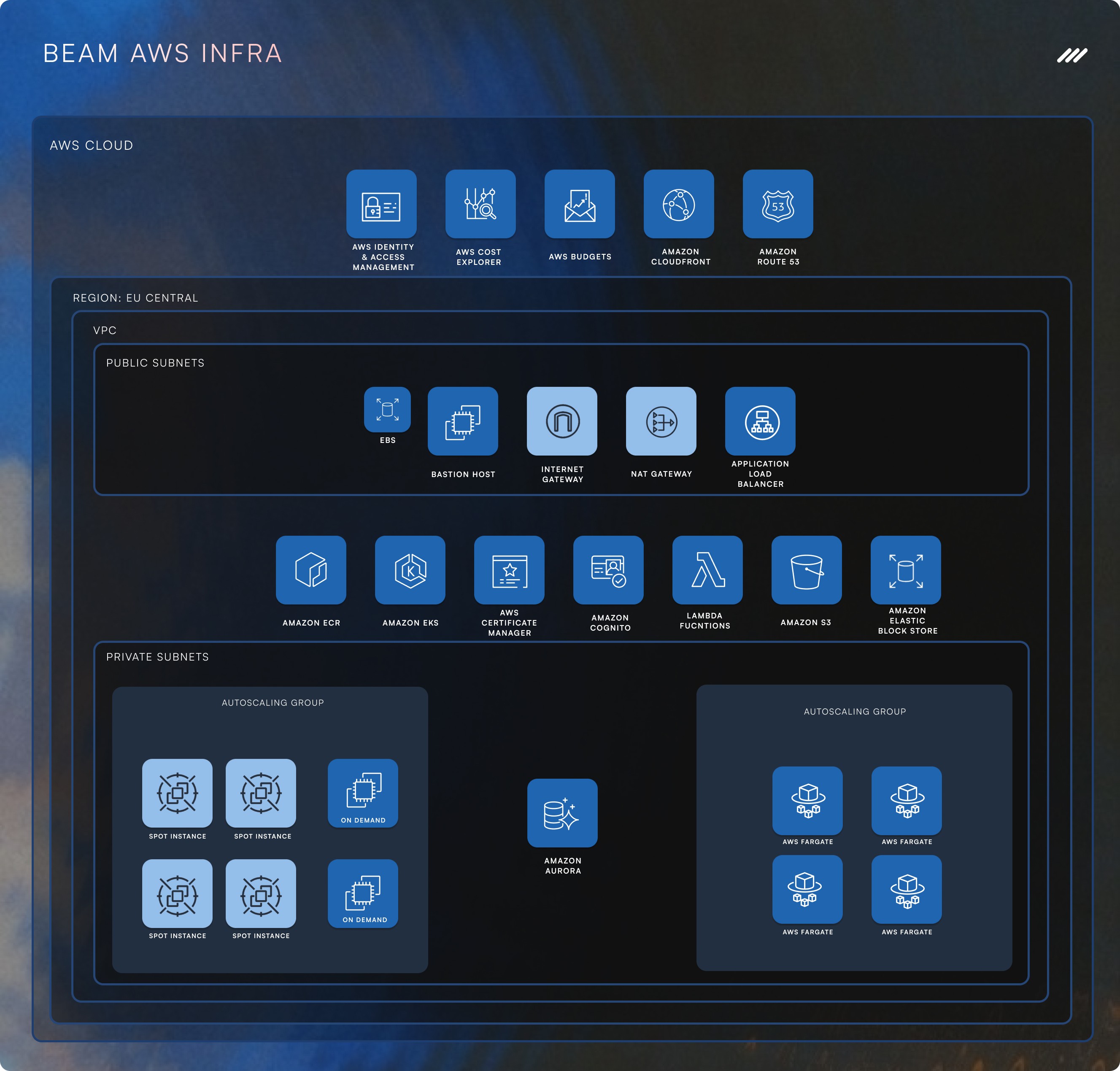
Die ersten Schwierigkeiten - Warum unser erstes System nicht skalieren konnte
Beam AI’s Backend verarbeitet riesige Datenmengen und führt Hintergrundaufgaben aus, die Arbeitsabläufe automatisieren und AI-gesteuerte Operationen ausführen. Aber in den frühen Tagen war unsere Architektur alles andere als skalierbar:
Dienste waren ressourcenhungrig, was die Anzahl der Aufgaben beschränkte, die wir verarbeiten konnten.
Wir waren auf interne HTTP-Anrufe angewiesen, was zu Ineffizienzen und potenziellen Ausfällen führte.
Unser System fehlte die Fehlertoleranz, was bedeutete, dass ein einziger Fehler einen gesamten Arbeitsablauf lahmlegen konnte.
Es war klar, dass wir eine radikale Überarbeitung benötigten.
Schritt 1: Kubernetes: Das Rückgrat unserer Skalierbarkeit
Unser erster großer Wandel war der Umstieg auf Kubernetes, das uns Folgendes bot:
→ Hohe Verfügbarkeit: Sicherstellung, dass Dienste auch bei Ausfällen einzelner Komponenten weiterlaufen.
→ Zero-Downtime-Bereitstellungen: Wir konnten Updates durchführen, ohne den Betrieb zu stören.
→ Fehlerisolierung: Ein ausfallender Dienst beeinträchtigt nicht das gesamte System.
Durch die Orchestrierung unserer Workloads mit Kubernetes haben wir einen bedeutenden Engpass beseitigt und eine skalierbare Grundlage für Wachstum geschaffen.
Schritt 2: Nachrichtenbroker: Ersetzen von synchronen Aufrufen durch intelligentes Queuing
Ursprünglich kommunizierten die Dienste von Beam AI über direkte HTTP-Anrufe, wodurch enge Abhängigkeiten und Einzelpunkte des Versagens entstanden. Die Lösung? Ein Nachrichtenbroker.
Mit einer nachrichtengetriebenen Architektur gewannen wir:
→ Asynchrone Verarbeitung: Dienste lauschen auf Nachrichten, anstatt auf direkte Antworten zu warten.
→ Lastmanagement: Wir können begrenzen, wie viele Aufgaben jeder Dienst gleichzeitig verarbeitet.
→ Aufgabenwiederherstellung: Wenn ein Dienst abstürzt, nimmt er seine Arbeit wieder dort auf, wo er aufgehört hat, sobald er neu startet.
Diese Änderung verwandelte unsere Effizienz, indem sie es Diensten ermöglichte, ohne sich gegenseitig zu blockieren oder zu überlasten, zu kommunizieren.
Schritt 3: Laufzeitmodellwechsel: AI kosteneffizienter machen
AI-Modelle sind mächtig, aber diese blind für jede Aufgabe zu verwenden ist ein Kosten- und Leistungsalbtraum. Wir entwickelten ein dynamisches Modellswitching-System, das:
→ Wählt LLMs basierend auf der Länge und Komplexität des Dokuments.
→ Verwendet verschiedene Modelle für verschiedene Dokumenttypen, um Geschwindigkeit und Genauigkeit zu optimieren.
→ Reduziert Ratenbeschränkungen und API-Kosten, indem das richtige Modell für die jeweilige Aufgabe verwendet wird.
Dieser Ansatz erhöhte nicht nur die Leistung, sondern machte unser System auch kosteneffektiver, ohne an Qualität einzubüßen.
Schritt 4: Aufgaben in Teile zerlegen für maximale Zuverlässigkeit
Skalierung bedeutet nicht nur, mehr zu tun, sondern mehr zu tun, während man widerstandsfähig bleibt. Wir haben die monolithische Aufgabenausführung in unabhängige Schritte unterteilt, sodass:
→ Jede Phase Fortschritte an den Nachrichten-Broker meldet.
→ Fehlgeschlagene Aufgaben vom letzten abgeschlossenen Schritt neu starten können anstatt von vorne zu beginnen.
→ Parallele Ausführung möglich ist, was die Effizienz steigert.
Dies gab uns eine feinkörnige Kontrolle über Automatisierungs-Workflows und machte Beam AI zuverlässiger als je zuvor.
Schritt 5: Datenbankoptimierung: Umstieg auf PostgreSQL mit Vektorunterstützung
Die Handhabung großer Mengen strukturierter und unstrukturierter Daten erforderte ein Umdenken unserer Speicherstrategie. Anfangs nutzten wir einen Mix aus Vektordatenbanken, wechselten jedoch zu PostgreSQL mit Vektorunterstützung für:
→ Schnellere Suchen und Abrufe von Einbettungen für KI-Modelle.
→ Zentralisierten Speicher, der die Datenbankfragmentierung reduziert.
→ Bessere Indizierung für kontextbewusste Automatisierung.
Dieser Schritt vereinfachte unsere Architektur, ohne Leistungseinbußen zu verursachen.
Schritt 6: Benutzerdefinierter API-Ausführer: Automatisierung externer Anrufe für Agenten
Um zu verbessern, wie unsere KI-Agenten mit externen APIs interagieren, haben wir einen benutzerdefinierten API-Ausführer entwickelt, der:
→ API-Anfragen effizient bearbeitet, ohne Workflows zu blockieren.
→ Wiederholungen und Fehler verwaltet, um Zuverlässigkeit sicherzustellen.
→ Nahtlos in unseren Automatisierungs-Stack integriert.
Dies gewährleistete reibungslose Interaktionen zwischen Beam AI und externen Diensten, wodurch unsere Automatisierung nahtloser und robuster wurde.

Die Auswirkung: Von 50 Aufgaben zu über 5.000 Aufgaben pro Minute
Mit diesen architektonischen Änderungen erlebte Beam AI einen massiven Sprung in der Skalierbarkeit. Wir gingen von der Verarbeitung von weniger als 50 Aufgaben gleichzeitig zu über 5.000 Aufgaben pro Minute – ein 100-facher Anstieg der Kapazität.
LLMOps: Das Geheimnis skalierbarer KI-Automatisierung
Die Skalierung KI-gesteuerter Workflows erfordert mehr als nur Infrastruktur-Upgrades, sie erfordert LLMOps Best Practices, um zu managen:
Leistungsoptimierung für optimale Genauigkeit und Geschwindigkeit.
Skalierungsrahmenwerke, die den steigenden Bedarf bewältigen.
Risikominimierung durch Überwachung, Katastrophenschutz und Sicherheitsbest Practices.
Effizienzsteigerungen durch Automatisierung und intelligente Ressourcenzuteilung.
Bei Beam AI steht LLMOps im Mittelpunkt unserer Skalierungsstrategie, sodass wir KI-Workflows effizient, kostengünstig und ohne Leistungseinbußen handhaben können.
Das Fazit: Skalierung ist ein kontinuierlicher Prozess
Skalierung ist kein einmaliges Ereignis, sondern ein laufender Prozess, Engpässe zu identifizieren, Infrastruktur zu optimieren und die richtigen Technologien zu nutzen. Durch die Einführung von Kubernetes, Nachrichten-Brokern, dynamischen Modellwechseln und optimierten Datenbanken haben wir ein System aufgebaut, das hohe Automatisierungsvolumen mit Stabilität und Effizienz bewältigen kann.
Bei Beam AI entwickeln wir unsere Architektur ständig weiter, um immer einen Schritt voraus zu sein. Wenn Sie ähnliche Skalierungsherausforderungen bewältigen, ist das wichtigste Fazit einfach: Entwickeln Sie für Widerstandsfähigkeit, automatisieren Sie intelligent und seien Sie immer bereit, sich anzupassen.




