6 Min. Lesezeit
Vibe Coding vs. Agentic Engineering im Jahr 2026: Was übersteht den Produktivbetrieb?


Kategorie
KI-Agenten
Artikel teilen
Vor achtzehn Monaten fühlte es sich noch wie ein Partytrick an, eine KI Ihren Code schreiben zu lassen. Man kopierte einen Prompt in ein Chatfenster, schaute zu, wie eine Funktion materialisierte, und teilte den Screenshot auf Twitter. Anfang 2025 gab Andrej Karpathy dieser Praxis einen Namen, Vibe Coding, und plötzlich hatte die halbe Branche die Erlaubnis, den Output nicht mehr zu lesen. Heute ist KI-gestützte Entwicklung der Standard-Workflow für die meisten Engineering-Teams, und die Frage hat sich von „Sollten wir es nutzen?“ zu „Wie verhindern wir, dass es unter seinem eigenen Gewicht zusammenbricht?“ verschoben.
Diese Frage spaltet die Branche in zwei Lager. Das eine Lager „vibed“. Das andere betreibt Engineering. Der Unterschied zwischen ihnen ist der Unterschied zwischen einer Demo, die Applaus erntet, und einem System, das sein erstes Quartal in der Produktionsumgebung übersteht.
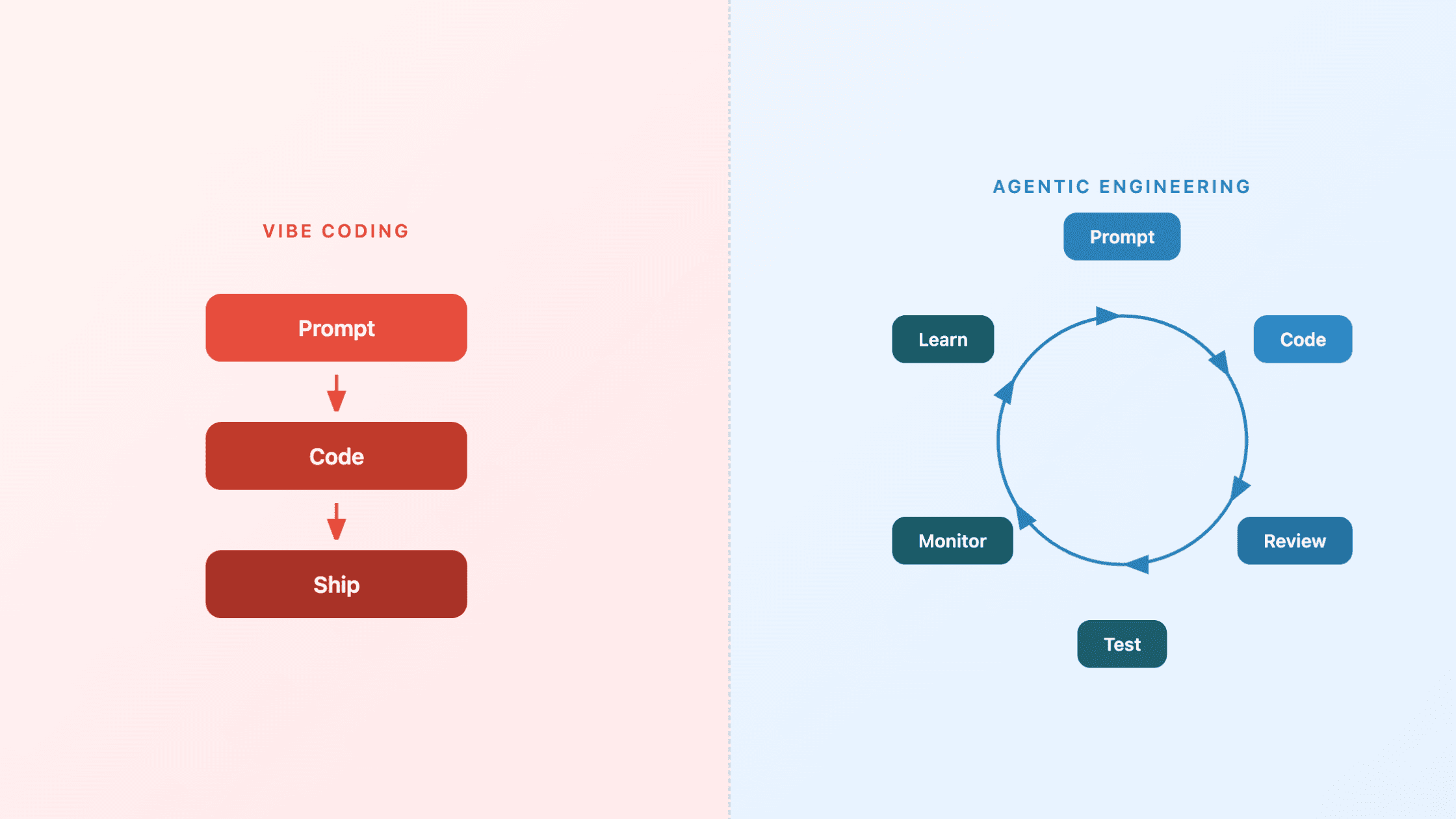
Was Vibe Coding eigentlich ist
Karpathys ursprüngliche Beschreibung war entwaffnend ehrlich: Man führt ein Gespräch in natürlicher Sprache mit einer KI, akzeptiert den erzeugten Code, führt ihn aus, und wenn etwas schiefgeht, kopiert man die Fehlermeldung wieder hinein und lässt die KI den Fehler beheben. Keine manuelle Codereview. Keine Architekturplanung. Man „gibt sich voll und ganz den Vibes hin“ und lässt sich vom Modell tragen.
Innerhalb eines engen Rahmens funktioniert dieser Ansatz hervorragend. Prototypen, persönliche Tools, Hackathon-Beiträge, Wochenendprojekte und Lernübungen profitieren alle von der Geschwindigkeit des Vibe Codings. Wenn wenig auf dem Spiel steht und man selbst die Zielgruppe ist, ist das Überspringen des Review-Zyklus ein rationaler Kompromiss. Man tauscht Gründlichkeit gegen Geschwindigkeit und hat an einem Nachmittag etwas Funktionierendes in der Hand.
Das Problem beginnt, wenn dieses Nachmittagsprojekt befördert wird. Jemand stellt es einem Kunden vor. Jemand anderes wünscht sich ein neues Feature. Eine dritte Person muss sechs Wochen später ohne jeglichen architektonischen Kontext den Fehler suchen. An diesem Punkt funktionieren die Vibes nicht mehr.
Wie Agentic Engineering aussieht
Agentic Engineering ist das, was passiert, wenn Profis KI als Kraftmultiplikator nutzen, während sie die volle Verantwortung für Architektur, Qualität und Urteilsvermögen behalten. Die KI generiert Code, entwirft Tests, schlägt Refactorings vor und beschleunigt jede Phase des Entwicklungslebenszyklus. Aber ein Mensch bleibt für Designentscheidungen, Sicherheitsüberprüfungen und systemnahes Denken im Loop.
Dies ist keine langsamere Version von Vibe Coding. Es ist ein grundlegend anderes Betriebsmodell. Vibe Coding optimiert für das sofortige Ergebnis. Agentic Engineering optimiert für Korrektheit, Wartbarkeit und die langfristige Systemintegrität. Die KI übernimmt mehr von der mechanischen Arbeit, aber der Engineer trägt weiterhin die Verantwortung für das Ergebnis.
Die Unterscheidung ist wichtig, weil laut Microsofts Work Trend Index 2026 inzwischen 78 % der Wissensarbeiter wöchentlich KI-Agenten nutzen. KI-gestützte Arbeit ist kein Experiment mehr. Sie ist die Produktionsumgebung. Und Produktionsumgebungen erfordern Engineering-Disziplin, keine Vibes.
Wo Vibe Coding an seine Grenzen stößt
Das Fehlermuster ist vorhersehbar und gut dokumentiert. Simon Willison, eine der angesehensten Stimmen in der Entwickler-Community, räumte kürzlich ein, dass er aufgehört hatte, KI-generierten Produktionscode zu reviewen, und erkannte das Muster als „Normalization of Deviance“ (Normalisierung der Abweichung) – die schrittweise Akzeptanz niedrigerer Standards, bis etwas schiefgeht. Willisons Ehrlichkeit ist wertvoll, weil sie zeigt, dass selbst erfahrene, disziplinierte Entwickler abdriften, wenn das Ergebnis plausibel genug aussieht.
Die Daten stützen diese Sorge. Eine Oxford-Studie zur Feinabstimmung von KI-Systemen auf benutzerfreundliches Verhalten ergab, dass die Optimierung auf Nahbarkeit das Modell um 60 % anfälliger für falsche Antworten machte, was die Fehlerraten um 7,43 Prozentpunkte erhöhte. Modelle, die sich richtig anfühlen, sind nicht zwangsläufig Modelle, die richtig liegen. Beim Vibe Coding ist das primäre Qualitätssignal des Entwicklers „Sieht das vernünftig aus?“ – genau die Art von oberflächlicher Prüfung, für deren Bestehen freundlicher, selbstbewusster KI-Output konzipiert ist.
Selbst die besten Modelle stoßen an harte Grenzen. GPT-5.5 erreichte bei OSWorld-Desktop-Automatisierungsaufgaben 75 % und entsprach damit dem menschlichen Durchschnittsniveau. Das klingt beeindruckend, bis man das Gegenteil betrachtet: eine Fehlerquote von 25 % bei Routineaufgaben. Für einen Prototyp ist ein Fehler von eins zu vier ein Kuriosum. Für ein Produktionssystem, das Tausende von Transaktionen verarbeitet, ist es ein untragbares Risiko.
Die Produktionslücke, mit der niemand geplant hat
Der gesamte Softwareentwicklungszyklus wurde um eine Kernannahme herum entwickelt: Das Schreiben von Code ist langsam und teuer. Codereviews, Tests, Deployment-Pipelines, Dokumentationsanforderungen – all dies existiert, weil die Erstellung von Code früher der Flaschenhals war, der den Teams Zeit zum Nachdenken gab.
Dieser Flaschenhals ist weg. Beam AI und andere KI-Lösungen generieren Code schneller, als ein Team ihn reviewen kann, und die Infrastruktur, die um die langsame Produktion herum aufgebaut wurde, ist noch nicht hinterhergekommen. Die neuen Engpässe liegen im Upstream und Downstream. Im Upstream entscheidet die Qualität der Spezifikationen und Designentscheidungen darüber, ob die KI das Richtige produziert. Im Downstream bestimmen Evaluierung, Tests und Monitoring, ob das Richtige auch im Laufe der Zeit richtig bleibt.
Dadurch entsteht eine subtile, aber gefährliche Lücke. Die traditionellen Signale für Codequalität – saubere Commit-Historie, erfolgreiche Test-Suites, aktuelle Dokumentation – weisen nicht mehr zuverlässig darauf hin, dass ein Mensch verstanden hat, was gebaut wurde. Eine KI kann all diese Artefakte erzeugen, ohne dass jemals ein Mensch über das Verhalten des Systems in Grenzfällen nachgedacht hat. Das Risiko eines unbemerkten Systemausfalls summiert sich schnell, wenn niemand darauf achtet.
Was Unternehmen tatsächlich benötigen
Für Unternehmen, die KI-Agenten in reale Workflows integrieren, lautet die Antwort weder „Nutzen Sie keine KI für Code“ noch „Reviewen Sie alles manuell“. Beide Extreme scheitern bei der Skalierung. Die Antwort lautet Agentic Engineering, gestützt auf drei betriebliche Anforderungen.
Kontinuierliche Genauigkeitsüberwachung. KI-Agenten, die in der Produktion arbeiten, müssen kontinuierlich an der Realität gemessen werden, nicht nur einmalig beim Deployment. Modelle verändern sich. Datenverteilungen verschieben sich. Ein System, das im März gut functioniert hat, kann im Mai unbemerkt nachlassen. Selbstlernende Systeme, die diese Verschiebungen erkennen und sich anpassen, übertreffen statische Installationen bei weitem.
Automatisierte Feedback-Loops. Wenn ein KI-Agent einen Fehler macht, muss dieser Fehler in den Lernzyklus des Systems zurückfließen, ohne dass ein Mensch manuell neu trainieren oder patchen muss. Das ist der Unterschied zwischen KI-Agenten, die sich im Laufe der Zeit verbessern, und KI-Agenten, die dieselben Fehler in großem Stil wiederholen. Die Feedbackschleife macht aus einem Werkzeug ein Teammitglied.
Nachvollziehbare Entscheidungspfade. Jede Aktion, die ein KI-Agent in einer Produktionsumgebung ausführt, sollte nachvollziehbar sein. Nicht aus Compliance-Gründen, sondern weil das Debuggen eines Systems, das man nicht inspizieren kann, teuer und langsam ist. Wenn ein Mensch-KI-Team sehen kann, warum ein Agent eine Entscheidung getroffen hat, kann es den Kurs in Minuten statt in Tagen korrigieren.
Was jetzt zu tun ist
Wenn Ihr Team Prototypen und interne Tools per Vibe Coding entwickelt, machen Sie weiter so. Die Geschwindigkeitsgewinne sind real, und das Risikoprofil ist für temporäre Arbeiten angemessen.
Wenn Ihr Team KI-generierten Code in die Produktion einbringt oder KI-Agenten in geschäftskritischen Workflows einsetzt, wenden Sie das Agentic-Engineering-Modell an. Das bedeutet drei sofortige Änderungen:
Erstens: Führen Sie wieder menschliche Reviews für Produktionspfade ein. Nicht jede Zeile erfordert eine manuelle Überprüfung, aber bei jeder Entscheidung auf Systemebene, jeder Sicherheitsgrenze und jedem Datenfluss sollte ein Mensch in der Lage sein zu erklären, warum es funktioniert.
Zweitens: Integrieren Sie die Evaluierung in die Deployment-Pipeline, nicht danach. Genauigkeitsmetriken, Regressionstests und Verhaltensprüfungen sollten das Deployment genauso absichern wie Unit-Tests heute. Wenn Sie nicht messen können, ob Ihr Agent korrekt arbeitet, können Sie auch nicht behaupten, dass er es tut.
Drittens: Behandeln Sie das Agenten-Monitoring als geschäftskritische betriebliche Aufgabe. Dieselbe Aufmerksamkeit, die Ihr Team der Betriebszeit und Latenz widmet, muss auch der Genauigkeit und Entscheidungsqualität des Agenten zukommen. Eine Plattform mit integrierter Governance und kontinuierlichem Lernen nimmt Ihnen hier den größten Teil des manuellen Aufwands ab.
Vibe Coding hat der Branche eindrucksvoll vor Augen geführt, was KI leisten kann. Agentic Engineering ist der Weg, diese Produktionskapazität vertrauenswürdig zu machen. Die Unternehmen, die den zweiten Schritt meistern, während alle anderen noch vom ersten beeindruckt sind, werden die nächsten fünf Jahre des KI-Einsatzes bestimmen.
Die Vibes haben Spaß gemacht. Jetzt bauen Sie etwas, das Bestand hat.




