6 Min. Lesezeit
Prompt-Tuning über Domänen hinweg skalieren: Wie Clustering mit weniger Aufwand eine höhere Genauigkeit ermöglichte

Kategorie
KI-Agenten
Artikel teilen
Jedes Team, das LLM-gestützte Tools entwickelt, steht früher oder später an einem Wendepunkt: Das System, das für einen einzelnen Bereich hervorragend funktioniert, beginnt zu versagen, sobald es mehrere Bereiche gleichzeitig abdecken soll.
Unser Auto-Tuner — die Engine hinter Beams Prompt-Optimierung — liefert bei Single-Domain-Tools eine Genauigkeit von bis zu 98 %. Doch als unsere Nutzer begannen, umfassendere Agents zu entwickeln, reichte der Single-Domain-Ansatz nicht mehr aus.
Der Wandel: Von Task Agents zu Job Agents
Anfangs bauten Nutzer eng abgegrenzte Agents — ein Tool pro Aufgabe. Ein Datums-Parser. Ein Namens-Extraktor. Ein Schema-Validator. Jedes Tool hatte ein klar umrissenes Problem, und das Nutzerfeedback bündelte sich natürlicherweise in einer einzelnen Domäne.
Dann begannen Nutzer, breiter zu bauen. Statt fünf Agents mit jeweils einer Aufgabe entwickelten sie einen Agent, der eine komplette Jobfunktion übernimmt — Rechnungsverarbeitung, Compliance-Prüfung, Onboarding-Koordination. Ein einzelnes Tool, das mehrere Dokumenttypen, mehrere Formatkonventionen und mehrere Erfolgskriterien verarbeitet.
Das ist eine natürliche Entwicklung. LLMs sind inzwischen leistungsfähig genug, dass ein einzelner, gut formulierter Prompt leisten kann, wofür früher eine Pipeline aus eng spezialisierten Komponenten nötig war.
Das Problem: Unser Tuner optimierte diese Multi-Domain-Tools so, als würde das gesamte Feedback zu einem einzigen Problemraum gehören.
Warum Multi-Domain-Feedback Single-Domain-Tuning aushebelt
Wenn Feedback aus verschiedenen Domänen zusammengeworfen wird, laufen drei Dinge schief:
Konfligierende Optimierungssignale. Eine Korrektur der Datumsformatierung für Rechnungen und eine Korrektur der Datumsformatierung für Compliance-Dokumente können völlig unterschiedliche Lösungen erfordern. Gemittelt entsteht ein Kompromiss, der keines von beidem vollständig löst.
Unsichtbare Regressionen. Der Tuner verbessert die Gesamtgenauigkeit, aber die Leistung in einer Domäne verschlechtert sich unbemerkt. Die aggregierte Metrik sieht gut aus. Die Performance einzelner Domänen nicht.
Abnehmender Ertrag pro Aufwand. Ohne Domänenbewusstsein muss jeder Optimierungszyklus jedes Feedback-Element gleichzeitig verarbeiten. Der Fortschritt ist langsam, und das System kann die Domänen mit dem größten Handlungsbedarf nicht priorisieren.
Bei Single-Domain-Tools erreichte unser Tuner seine Genauigkeitsziele effizient. Bei Multi-Domain-Tools konnte er sie zwar ebenfalls erreichen — benötigte dafür aber mehr Zyklen und lieferte weniger stabile Ergebnisse. Es musste einen besseren Ansatz geben.
Die Erkenntnis: Erst clustern, dann tunen
Der Durchbruch war die Erkenntnis, dass Multi-Domain-Feedback nicht schwerer zu optimieren ist — sondern schwerer zu strukturieren. Sobald Feedback sauber nach Domänen organisiert ist, ist jedes einzelne Tuning-Problem nicht schwieriger als im Single-Domain-Fall.
Wir haben eine Clustering-Schicht eingeführt, die zwischen Feedback-Erfassung und Optimierung liegt. Bevor der Tuner überhaupt ein Feedback sieht, gruppiert die Clustering-Schicht es nach Domänen — Rechnungsverarbeitung, Compliance-Dokumente, Onboarding-Formulare — und erzeugt ein Label, das beschreibt, wofür jeder Cluster steht.
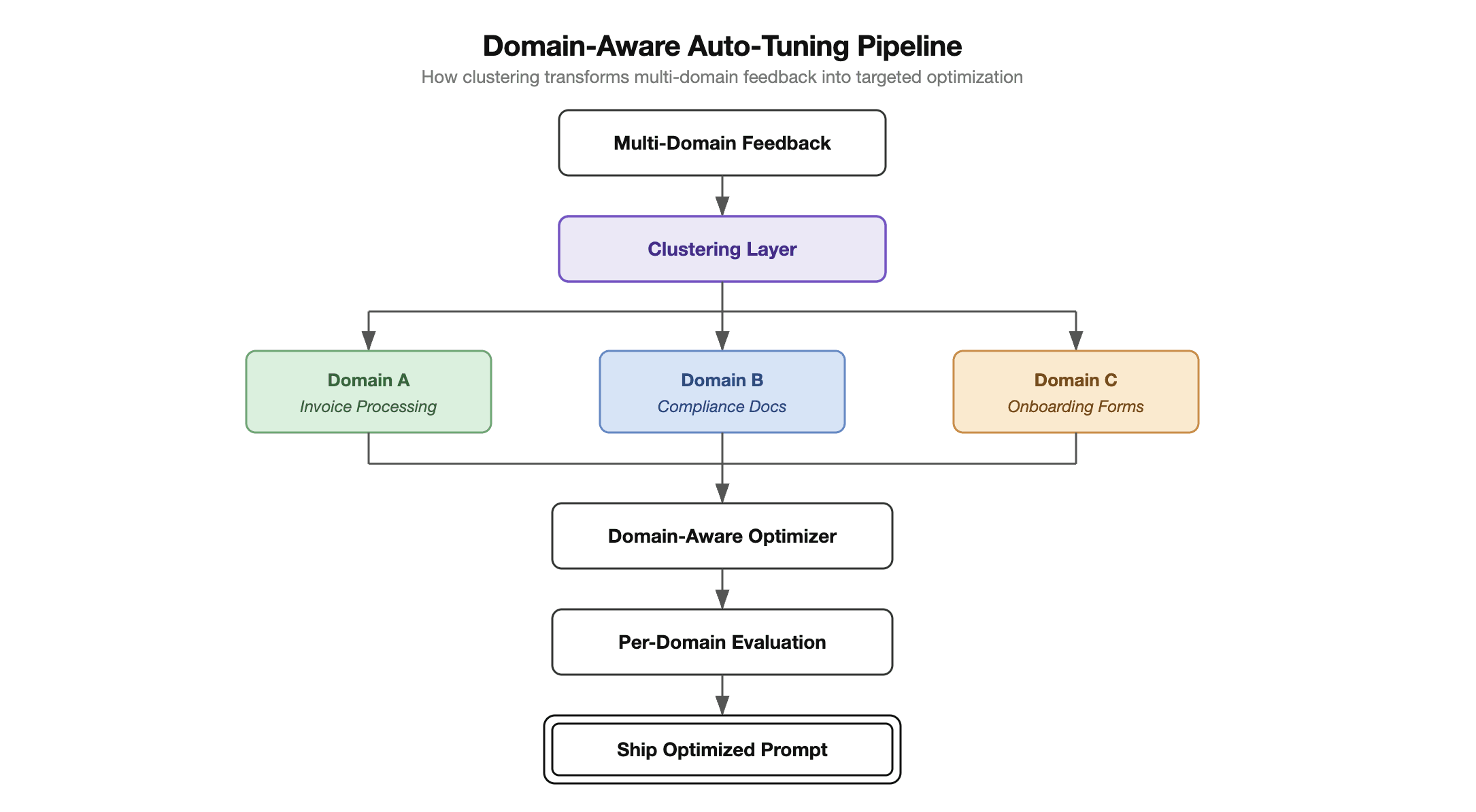
Das klingt unkompliziert. Die eigentlichen Herausforderungen stecken im Detail.
Herausforderung 1: Hochwertige Cluster-Labels sicherstellen
Bei Single-Domain-Tools sind Kategorien vorhersehbar. Bei Multi-Domain-Tools, die von verschiedenen Teams für unterschiedliche Zwecke gebaut werden, ergeben sich Domänen aus den Anforderungen der jeweiligen Stellenbeschreibung des Nutzers — und sie verändern sich mit der Weiterentwicklung von Workflows.
Das bedeutet, Cluster-Labels können nicht vordefiniert sein. Sie müssen dynamisch erzeugt werden. Und dynamisch erzeugte Labels bringen einen neuen Fehlermodus mit sich: ein Label, das plausibel klingt, aber nicht wirklich erfasst, was das Feedback gemeinsam hat.
Unser Ansatz behandelt Labeling als iterativen Verfeinerungsprozess statt als einmalige Klassifikation. Wenn neues Feedback eintrifft, erzeugt das System Kandidaten-Labels, prüft sie hinsichtlich Kohärenz mit bestehenden Clustern und verfeinert sie, wenn der Kohärenz-Score unter den Schwellenwert fällt.
Das zentrale Prinzip: Ein Cluster-Label ist ein Vertrag mit dem Optimierer. Es verspricht: „Alles Feedback in dieser Gruppe hat dieselbe Grundursache.“ Wir validieren diesen Vertrag kontinuierlich. Wenn die Verbesserungen des Optimierers für einen Cluster nicht mit tatsächlichen Genauigkeitsgewinnen in dieser Domäne korrelieren, ist das ein Signal, dass das Label verfeinert werden muss.
Dadurch entsteht ein selbstkorrigierender Zyklus: Die Ergebnisse des Optimierers fließen in die Label-Qualität zurück, was die Eingaben des Optimierers im nächsten Zyklus verbessert.
Herausforderung 2: Domänenbewusstes Training und Validierung
Clustering organisiert Feedback nicht nur — es verändert grundlegend, wie Training und Validierung funktionieren.
Training mit Domänenkontext
In der bisherigen Pipeline erhielt der Optimierer sämtliches Feedback auf einmal und erzeugte ein einziges Set an Prompt-Verbesserungen. Mit Clustering arbeitet das Training in jeder Phase domänenbewusst:
Zielgerichtete Analyse. Jeder Cluster erzeugt seine eigene Ursachenanalyse. Statt „Nutzer sind mit der Ausgabequalität unzufrieden“ identifiziert das System: „Feedback zur Rechnungsverarbeitung zeigt konsistente Fehler bei mehrzeiligen Positionen mit Teilmengen.“
Priorisierte Optimierung. Das System verteilt Optimierungsaufwand proportional. Ein Cluster mit 50 Feedback-Elementen und sinkender Genauigkeit erhält mehr Zyklen als ein stabiler Cluster mit 5 Elementen.
Konsolidierte Verbesserungen. Nach der unabhängigen Analyse jedes Clusters synthetisiert das System die Verbesserungen zu einem einheitlichen Prompt, der alle Domänen abdeckt. Das Ergebnis ist ein Prompt, nicht viele — aber er wurde mit vollständigem Bewusstsein für die Anforderungen jeder Domäne erstellt.
Validierung, die erkennt, was Aggregate übersehen
Betrachten wir dieses Szenario: Ein Optimierungszyklus verbessert die aggregierte Genauigkeit von 91 % auf 94 %. Doch die Rechnungsverarbeitung fällt von 96 % auf 88 % und wird von Gewinnen in anderen Domänen überdeckt.
Ohne Clustering könnte ein Optimierer die aggregierte Verbesserung sehen und ausrollen. Mit Clustering erkennt das System die Regression in der Rechnungsverarbeitung sofort und blockiert das Update.
Noch wichtiger: Das System verfolgt über Optimierungszyklen hinweg, welche Arten von Fehlern pro Domäne auftreten. Wenn die Rechnungsverarbeitung über mehrere Zyklen hinweg konsequent am selben Edge Case scheitert, wird dieses Muster als Signal sichtbar — nicht als Rauschen in aggregierten Metriken.
Die Validierungs-Pipeline bewertet jede Optimierung für jede Domäne unabhängig. Der Prompt wird erst ausgerollt, wenn jede Domäne ihren Genauigkeitsschwellenwert erfüllt.
Die Ergebnisse
Wir haben die domänenbewusste Pipeline mit unserem bisherigen Ansatz über Multi-Domain-AI Agents verglichen, die drei oder mehr unterschiedliche Dokumenttypen verarbeiten.
Drei Dinge stachen heraus:
Höhere Genauigkeitsobergrenze. Die geclusterte Pipeline erreicht bei Multi-Domain-Tools konsistent 98 %+. Das ist dieselbe Genauigkeit, die wir bei Single-Domain-Tools erzielt haben. Der bisherige Ansatz stagnierte bei etwa 89–91 %.
Deutlich weniger Optimierungszyklen. Weil jeder Zyklus auf spezifische Domänen mit spezifischen Problemen abzielt, ist der Fortschritt schneller. Multi-Domain-Tools konvergieren jetzt in etwa derselben Anzahl an Zyklen wie früher Single-Domain-Tools.
Regressionen wurden sichtbar und vermeidbar. Domänenübergreifende Regressionen wurden früher erst in der Produktion entdeckt; jetzt werden sie während der Validierung erkannt und blockiert. Das war der größte operative Gewinn.
Was das für Beam-Nutzer bedeutet
Für Teams, die auf Beam bauen, bleibt das weitgehend unsichtbar — und genau das ist der Punkt. Eure Multi-Domain-Agents lassen sich einfach besser tunen, konvergieren schneller und regressieren nicht stillschweigend.
Breitere Agents mit Vertrauen entwickeln. Der Tuner bewältigt jetzt die Komplexität der Multi-Domain-Optimierung, sodass ihr eure Architektur nicht mehr darum herum bauen müsst. Ein Agent, der eine komplette Jobfunktion übernimmt, ist nicht schwieriger zu tunen als ein enges Single-Task-Tool.
Vertraut auf Genauigkeit über alle eure Domänen hinweg. Die Validierung pro Domäne bedeutet, dass der Tuner keinen Teil eures Workflows opfert, um einen anderen zu verbessern. Jede Domäne muss bestehen, bevor eine Optimierung ausgerollt wird.
Rechnet mit schnellerer Konvergenz. Mit strukturierter, domänenbewusster Optimierung erreicht der Tuner seine Genauigkeitsziele in weniger Zyklen. Weniger Zeit fürs Tuning bedeutet mehr Zeit fürs Ausrollen.
Die Entwicklung von Single-Domain- zu Multi-Domain-Tuning bestand nicht darin, den Optimierer intelligenter zu machen. Es ging darum, dem Optimierer besser strukturierte Informationen bereitzustellen.
Während Agents ihren Umfang weiter ausbauen — mehr Domänen, mehr Dokumenttypen, mehr Edge Cases — ist die Fähigkeit, domänenübergreifend ohne Regressionen zu tunen, kein Nice-to-have. Sie ist das Fundament, das breitere Agents in der Produktion erst tragfähig macht.




