7 Min. Lesezeit
6 Multi-Agent-Orchestrierungsmuster, die in der Produktion tatsächlich funktionieren


Kategorie
KI-Agenten
Artikel teilen
Gartner meldete einen Anstieg um 1.445 % bei Anfragen zu Multi-Agenten-Systemen zwischen Q1 2024 und Q2 2025. Unternehmen setzen bereits durchschnittlich 12 Agenten ein, und diese Zahl soll innerhalb von zwei Jahren um 67 % steigen.
Doch 40 % der Multi-Agenten-Piloten scheitern innerhalb von sechs Monaten nach der Produktivsetzung. Das Muster ist nicht, dass Multi-Agenten-Systeme nicht funktionieren. Es ist, dass Teams das falsche Orchestrierungsmuster für ihr Problem wählen oder das richtige wählen, ohne zu verstehen, wie es scheitert.
Hier sind sechs Muster, die sich in der Produktion bewähren, sowie die konkreten Arten, wie jedes von ihnen scheitert, wenn es das nicht tut.
1. Orchestrator-Worker
Ein Agent erhält die Aufgabe, zerlegt sie in Teilaufgaben, delegiert jede an einen spezialisierten Worker und führt die Ergebnisse zusammen. Der Orchestrator nutzt ein leistungsfähiges Modell, während die Worker günstigere, aufgabenbezogene Modelle verwenden und so die Kosten um 40-60 % senken.
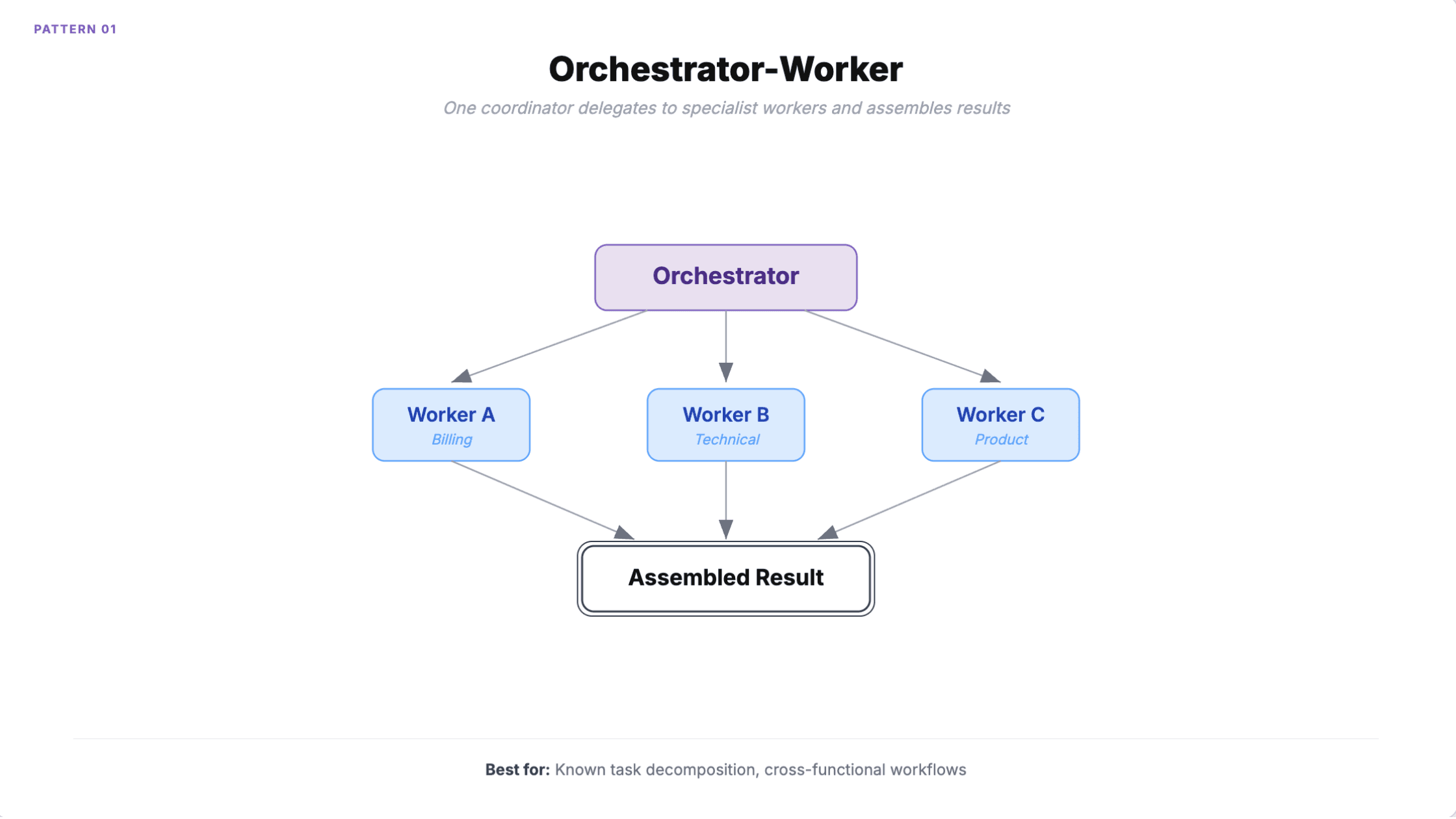
Wann man es einsetzen sollte: Funktionsübergreifende Workflows mit klarer Aufgabenteilung. Kundenservice-Routing zwischen Billing-, technischen und Produktspezialisten. Jede Aufgabe, bei der Sie einen einzelnen Verantwortlichkeitspunkt benötigen.
Wells Fargo nutzt dieses Muster, um 35.000 Bankern Zugang zu 1.700 Verfahren in 30 Sekunden zu geben, statt in 10 Minuten. Salesforce Agentforce 2.0 implementiert es über ihre Atlas Reasoning Engine.
Wie es scheitert
Der Orchestrator ist ein Single Point of Failure. Wenn er eine Aufgabe falsch klassifiziert, landet sie beim falschen Worker, und Fehlklassifikationen verstärken sich in großem Maßstab.
Der Überlauf des Kontextfensters ist das subtilere Problem. Der Orchestrator sammelt Kontext von jedem Worker. Ab vier oder mehr Workern wird das Kontextfenster häufig überschritten. Workflows, die im Test 0,50 $ kosten, können bei 100.000 Ausführungen 50.000 $/Monat erreichen, weil der Orchestrator zusätzlich zu jedem Worker-Aufruf mehrere LLM-Aufrufe für Zerlegung und Aggregation benötigt.
2. Sequentielle Pipeline
Agenten arbeiten in einer vordefinierten linearen Kette. Jeder verarbeitet die Ausgabe des vorherigen Agenten über einen gemeinsamen Zustand. Die Reihenfolge ist deterministisch und wird bereits im Design festgelegt.
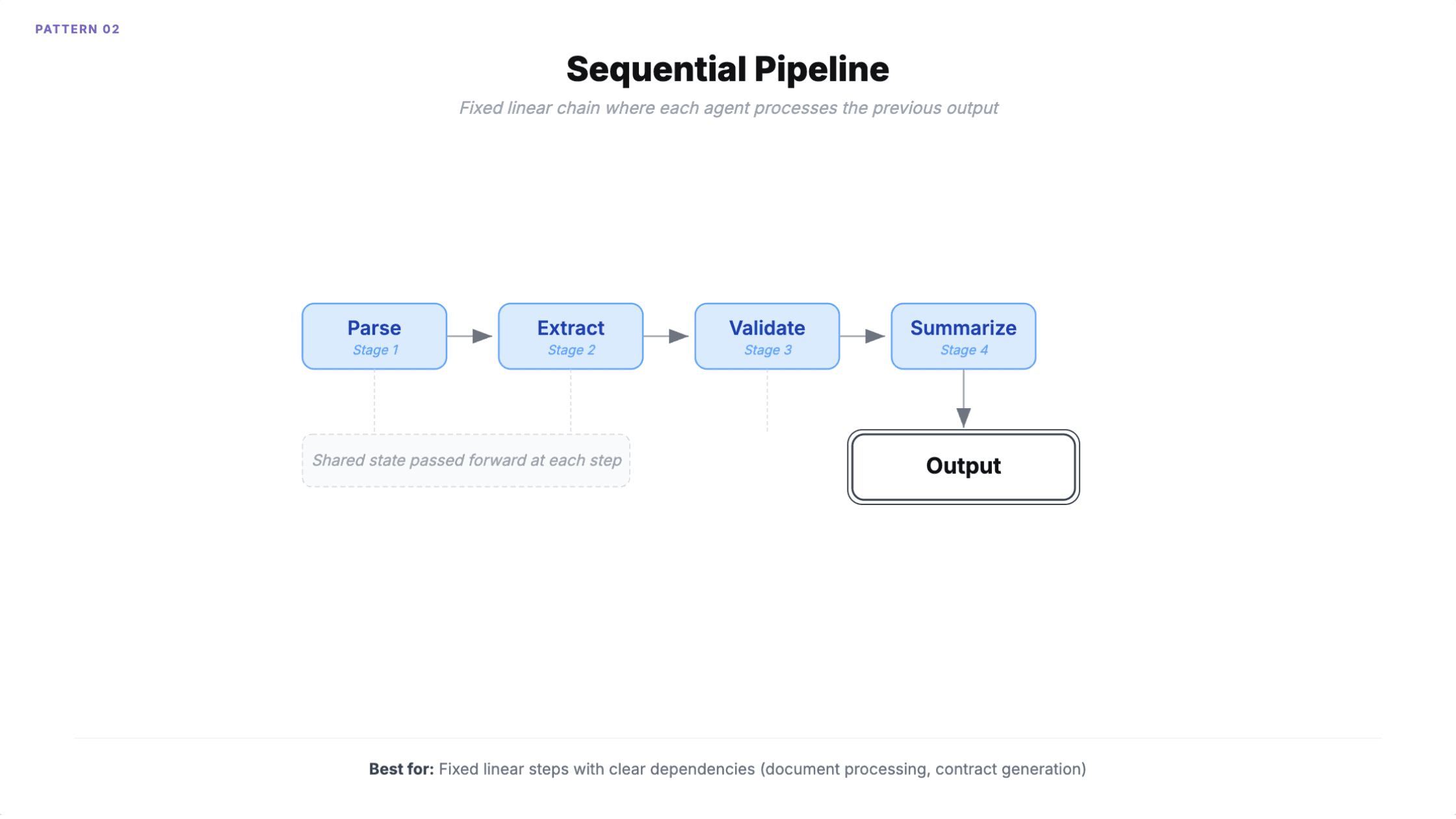
Wann man es einsetzen sollte: Dokumentenverarbeitung (parsen, extrahieren, validieren, zusammenfassen). Vertragserstellung. Inhaltsmoderation. Jeder mehrstufige Prozess mit klaren linearen Abhängigkeiten.
Das Azure Architecture Center von Microsoft dokumentiert eine Anwaltskanzlei, die dies für die Vertragserstellung nutzt: Vorlagenauswahl, Klauselanpassung, Compliance-Prüfung und Risikobewertung werden jeweils von einem separaten KI-Agent übernommen.
Wie es scheitert
Fehlerfortpflanzung. Ein schlechter Output in Phase 1 setzt sich ohne Rücksprung durch alle nachgelagerten Phasen fort.
Das weniger offensichtliche Problem ist der Overhead. Eine Pipeline mit vier Agenten häuft rund 950 ms Koordinations-Overhead an, während die eigentliche Verarbeitung 500 ms dauert. Eine Pipeline mit drei Agenten verbraucht 29.000 Tokens gegenüber 10.000 bei einem vergleichbaren Single-Agent-Ansatz. Wenn Ihre Pipeline die Spezialisierung nicht braucht, zahlen Sie das Dreifache für dasselbe Ergebnis.
3. Fan-out / Fan-in
Mehrere Agenten arbeiten gleichzeitig am selben Input oder an unabhängigen Teilaufgaben. Ein Dispatcher verteilt die Arbeit, ein Collector aggregiert die Ergebnisse mittels Abstimmung, gewichteter Zusammenführung oder LLM-basierter Synthese.
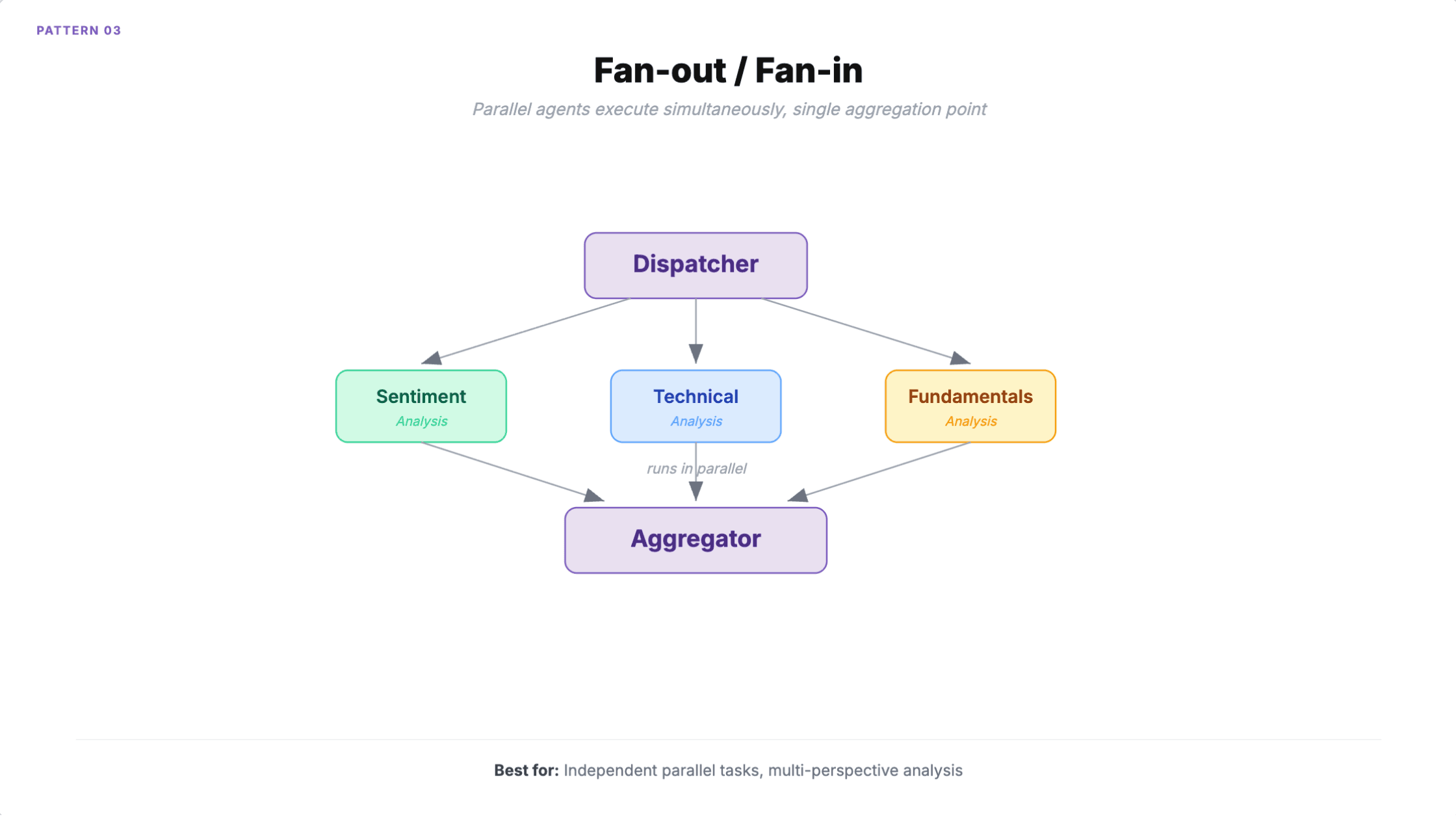
Wann man es einsetzen sollte: Analyse aus mehreren Perspektiven (Finanzanalyse mit parallel laufenden Fundamental-, Technical-, Sentiment- und ESG-Agenten). Gleichzeitiger Code-Review über Sicherheit, Stil und Performance. Jedes Szenario mit vier oder mehr unabhängigen Aufgaben, bei dem Sie die Durchlaufzeit um 75 % senken müssen.
Wie es scheitert
API-Rate-Limits. Fünfzehn gleichzeitige Agenten verbrauchen 150 Requests pro Sekunde, obwohl Ihr Limit bei 100 liegt. Jeder Agent bleibt einzeln innerhalb der Grenzen, aber die Gesamtauslastung überschreitet die Kapazität.
Race Conditions im gemeinsamen Zustand skalieren quadratisch. Ein System mit N Agenten hat N(N-1)/2 potenzielle gleichzeitige Interaktionen. Bei fünf Agenten sind das 10 potenzielle Konflikte. Bei zehn sind es 45.
Der Aggregationsschritt selbst führt Fehler ein. LLM-basierte Synthese kann einen Konsens halluzinieren, der in den zugrunde liegenden Ergebnissen nicht existiert. Wenn Ihre parallelen Agenten sich nicht einig sind (Sentiment sagt kaufen, Fundamentaldaten sagen verkaufen), brauchen Sie eine explizite Konfliktlösungsstrategie und nicht nur "die Ergebnisse zusammenfassen".
4. Multi-Agenten-Debatte
Mehrere Agenten nehmen an einer gemeinsamen Konversation teil, bringen Perspektiven ein, hinterfragen sich gegenseitig und verfeinern Positionen über mehrere Runden. Inklusive Maker-Checker-Schleifen, in denen ein Agent generiert und ein anderer validiert, bis die Freigabe erfolgt.
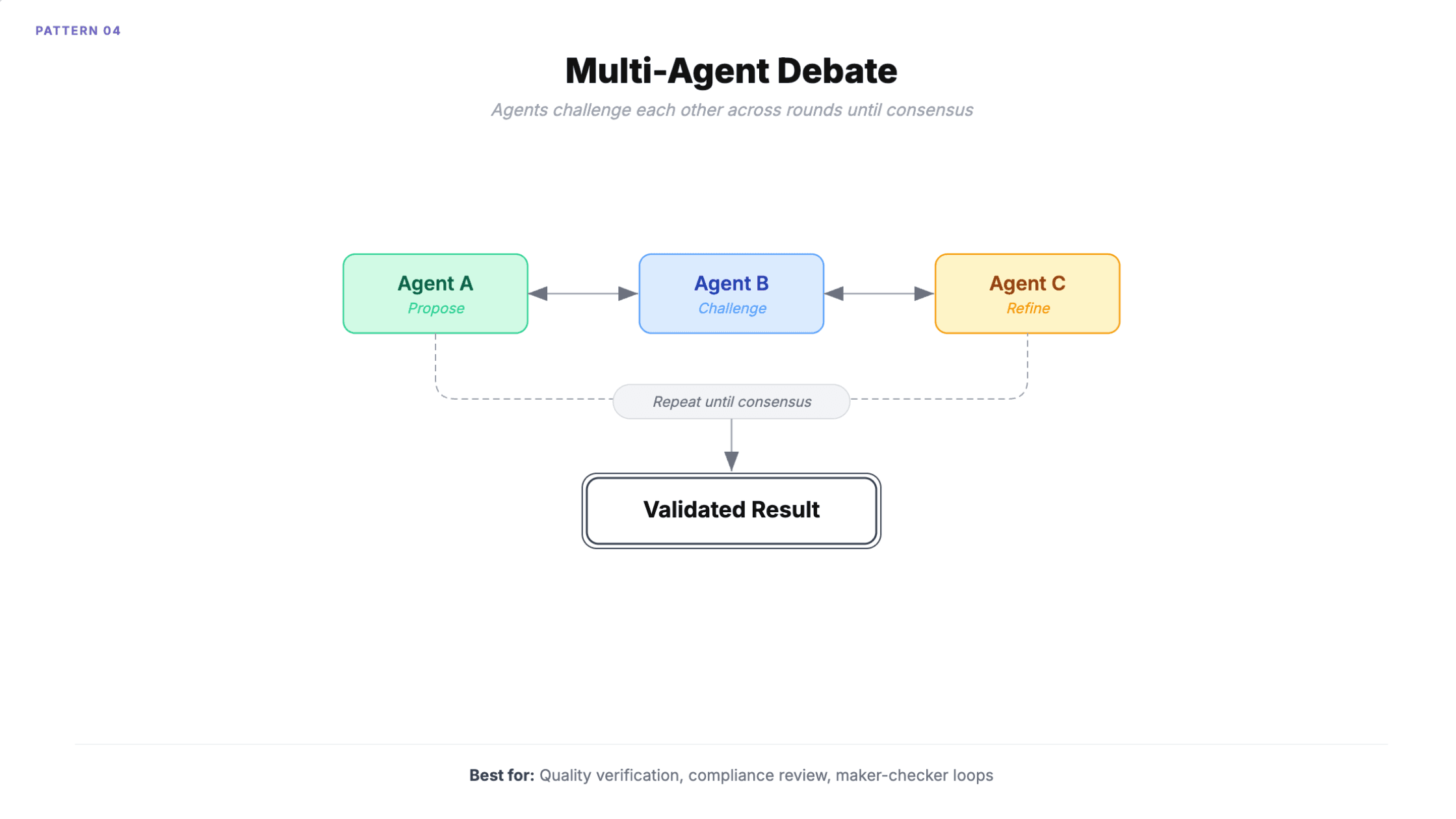
Wann man es einsetzen sollte: Compliance-Prüfungen, die mehrere Fachexperten-Perspektiven erfordern. Qualitätssicherung mit strukturiertem Review. Forschung zeigt, dass Debatten Halluzinationen im Vergleich zu Single-Model-Abfragen reduzieren, weil Agenten die Fehler der jeweils anderen erkennen.
Eine praktische Variante: Verwenden Sie ein günstiges, schnelles Modell für den Maker und ein leistungsfähiges Modell für den Checker. Sie erhalten den Qualitätsgewinn einer Debatte bei 40-60 % geringeren Kosten als beim Einsatz leistungsfähiger Modelle für beide Rollen.
Wie es scheitert
Konversationsschleifen. Agenten diskutieren weiter, ohne zu einem Ergebnis zu kommen. Microsoft empfiehlt aus diesem Grund, den Gruppenchat auf drei oder weniger Agenten zu begrenzen.
Kaskadierende Ja-Sager-Tendenzen sind das schwierigere Problem. Agenten neigen dazu, der Mehrheitsposition zuzustimmen, selbst wenn sie falsch ist, und erzeugen dadurch falschen Konsens. Fünf Runden mit drei Agenten bedeuten 15 LLM-Aufrufe pro Aufgabe, und das Ergebnis kann dennoch mit großer Sicherheit falsch sein, weil die Agenten die Fehler der jeweils anderen verstärkt haben.
5. Dynamische Übergabe
Jeder Agent bewertet die aktuelle Aufgabe und entscheidet, ob er sie selbst bearbeitet oder die Kontrolle an einen passenderen Spezialisten übergibt. Anders als beim Orchestrator-Worker gibt es keinen zentralen Koordinator. Agenten delegieren untereinander auf Basis des Laufzeitkontexts. Es ist immer nur ein Agent aktiv.
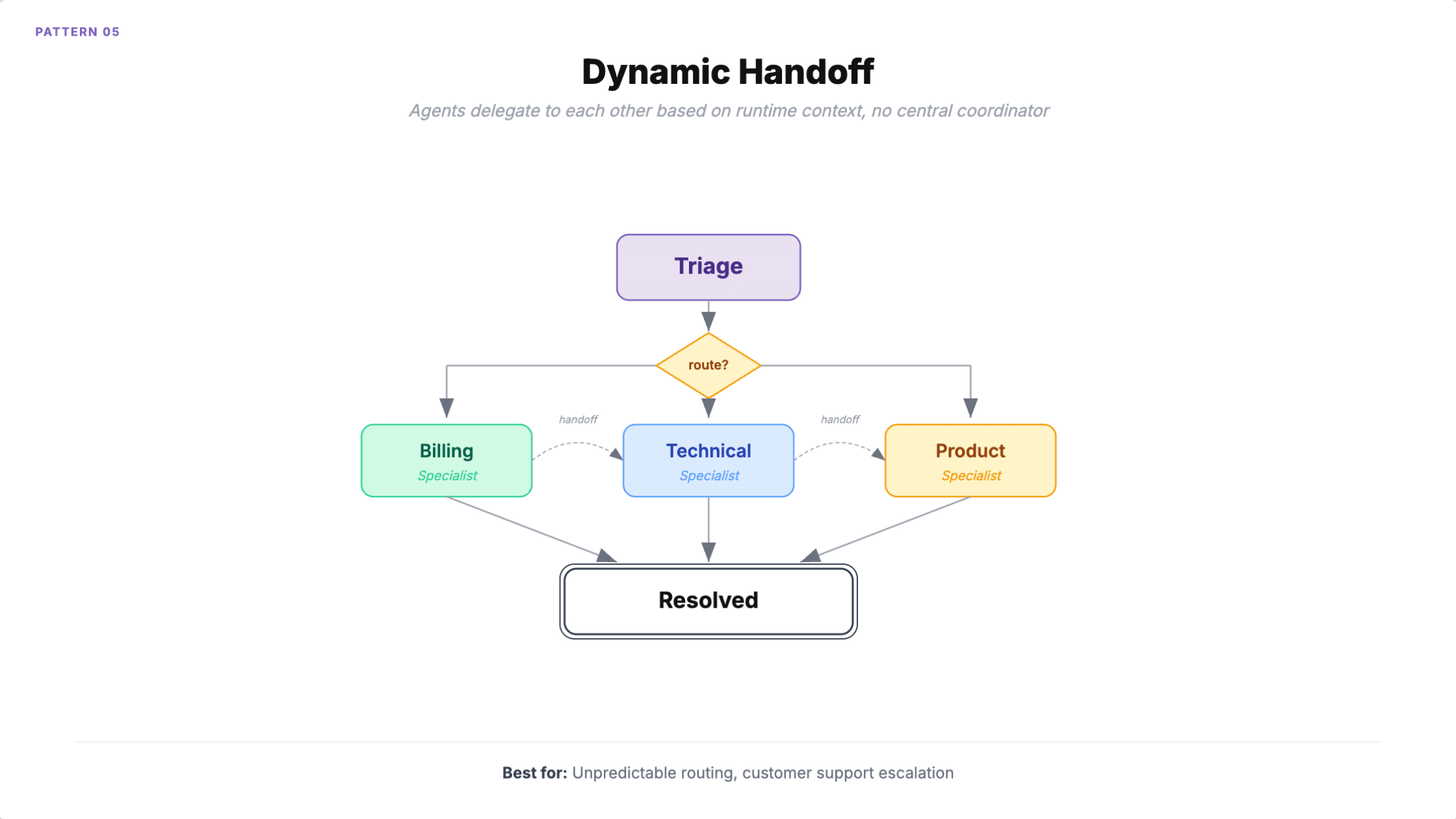
Wann man es einsetzen sollte: Kundensupport, bei dem während der Konversation der richtige Spezialist sichtbar wird (ein Billing-Problem entpuppt sich eigentlich als technisches Problem). Aufgaben, bei denen die benötigte Expertise im Voraus nicht bekannt ist.
HCLTech berichtete von 40 % schnellerer Falllösung durch dynamische Agentenübergabe. Das Muster funktioniert gut, wenn Sie zu Beginn wirklich nicht vorhersagen können, welcher Spezialist eine Interaktion benötigen wird.
Wie es scheitert
Endlose Übergabeschleifen. Agent A übergibt an B, B an C, C wieder an A. Das ist der häufigste Fehlerfall. Jeder Agent plant weiter um, weil niemand die Aufgabe verantwortet.
Kontextverlust summiert sich mit jeder Übergabe. Entweder Sie übergeben den vollständigen Kontext (teuer und irgendwann über den Fenstergrenzen) oder Sie fassen zusammen (verlustbehaftet, und die aufsummierten Zusammenfassungsfehler verschlechtern die Qualität). Und weil das Routing nicht deterministisch ist, kann derselbe Input völlig unterschiedliche Agentenketten erzeugen, was das Debugging nahezu unmöglich macht.
6. Adaptive Planung
Ein Manager-Agent erstellt, verfeinert und führt dynamisch einen Aufgabenplan aus, indem er Spezialisten konsultiert. Anders als beim Orchestrator-Worker, bei dem der Plan im Voraus bekannt ist, wird hier der Plan selbst durch Zusammenarbeit entdeckt. Der Manager iteriert, springt zurück und delegiert bei Bedarf und prüft kontinuierlich, ob das ursprüngliche Ziel erreicht wird.
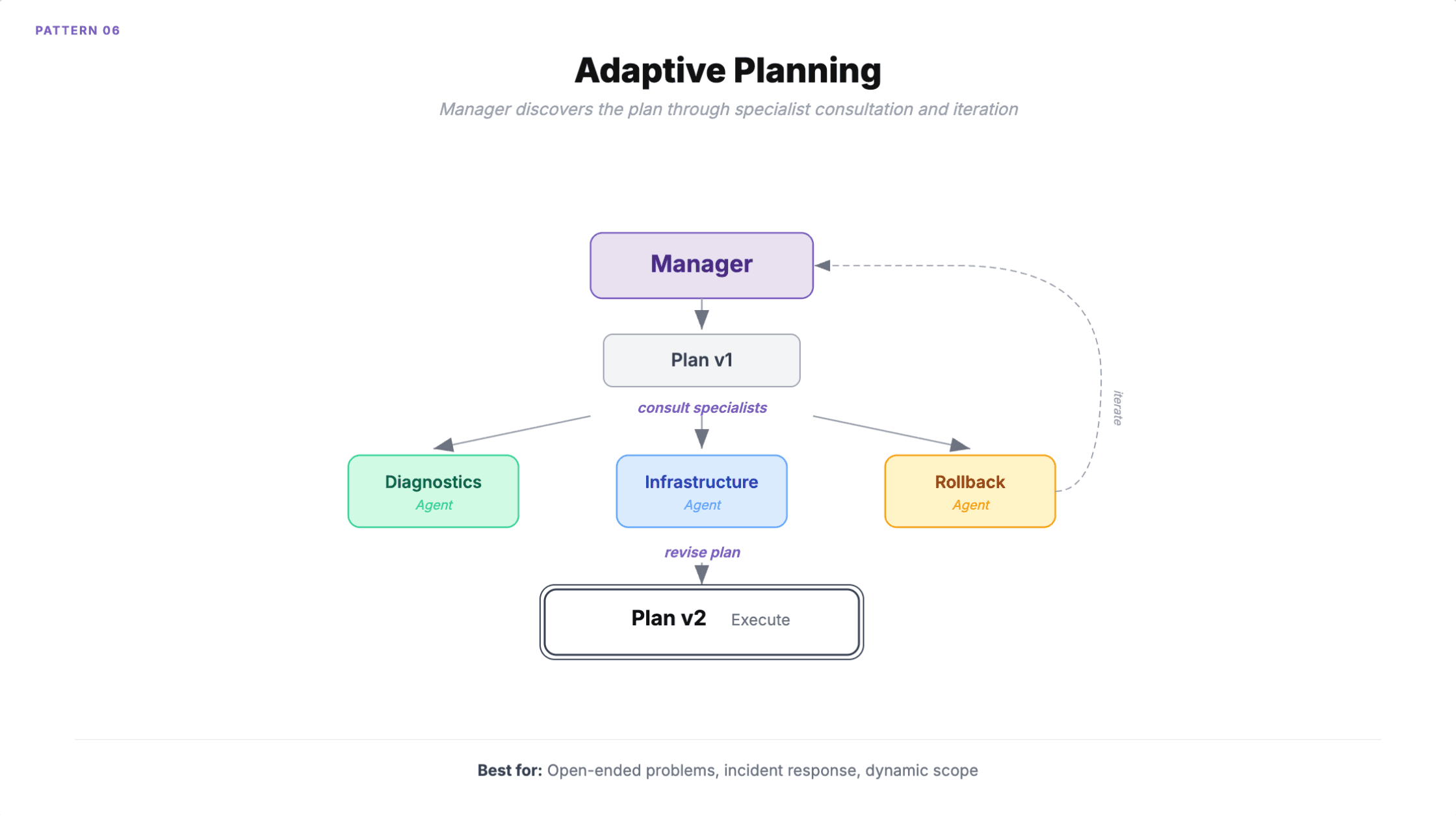
Wann man es einsetzen sollte: Offene Probleme ohne vorgegebenen Lösungsweg. Incident Response, bei der sich die Behebungsmaßnahmen aus der Diagnose ergeben. Komplexe Migrationen, bei denen sich der Umfang während der Ausführung ändert.
Microsoft dokumentiert ein SRE-Beispiel: Der Manager erstellt einen ersten Plan, konsultiert Diagnose- und Infrastruktur-Agenten, und wenn die Diagnose statt eines Deployment-Problems ein Datenbankproblem aufdeckt, schwenkt der gesamte Plan in Echtzeit um.
Wie es scheitert
Langsam bei der Konvergenz. Das Muster optimiert auf Korrektheit statt auf Geschwindigkeit. Zeitkritische Aufgaben eignen sich schlecht.
Zielabweichung ist der Produktions-Killer. Über mehrere Iterationen kann der verfeinerte Plan des Managers erheblich von der ursprünglichen Absicht abweichen. Backtracking verschärft das Problem: Wenn der Manager einen Irrweg entdeckt, ist die gesamte Arbeit dieses Zweigs vergeudete Rechenleistung, und die Kosten lassen sich im Voraus nicht zuverlässig vorhersagen. Wenn die ursprüngliche Anfrage unklar ist, kann der Manager in einer Endlosschleife versuchen, einen "vollständigen" Plan zu erstellen, der ein unzureichend spezifiziertes Ziel erfüllt.
Wie man das richtige Muster auswählt
Beginnen Sie mit dem einfachsten Muster, das zu Ihrem Problem passt. Die meisten Teams machen es unnötig komplex.
Bekannte Aufgabenteilung? Orchestrator-Worker. Sie kennen die Teilaufgaben bereits im Designstadium und möchten einen einzelnen Verantwortlichkeitspunkt.
Feste lineare Schritte? Sequentielle Pipeline. Die Reihenfolge ändert sich nie und jeder Schritt hängt vom vorherigen Output ab.
Unabhängige parallele Arbeit? Fan-out/Fan-in. Vier oder mehr Aufgaben ohne Abhängigkeiten untereinander.
Qualitätsprüfung erforderlich? Multi-Agenten-Debatte. Besonders Maker-Checker-Schleifen, bei denen Genauigkeit wichtiger ist als Geschwindigkeit.
Unvorhersehbares Routing? Dynamische Übergabe. Sie können erst im Verlauf der Konversation wissen, welcher Spezialist benötigt wird.
Offenes Problem? Adaptive Planung. Der Plan selbst muss entdeckt und nicht nur ausgeführt werden.
Princeton NLP fand heraus, dass ein einzelner Agent bei 64 % der benchmarkten Aufgaben mit Multi-Agenten-Systemen gleichzog oder sie übertraf, wenn ihm dieselben Tools und derselbe Kontext zur Verfügung standen. Multi-Agenten bringen 2,1 Prozentpunkte zusätzliche Genauigkeit bei ungefähr doppelten Kosten. Dieser Kompromiss lohnt sich bei komplexer domänenübergreifender Arbeit. Für alles andere ist ein gut gebauter einzelner KI-Agent einfacher, schneller und günstiger.
Das beste Orchestrierungsmuster ist das, das zu Ihrem tatsächlichen Problem passt, nicht das ausgefeilteste, das Sie bauen können.




