6 Min. Lesezeit
Ihr KI-Agent verliert in echten Gesprächen 39 % an Genauigkeit. Das herausragende Paper der ICLR 2026 erklärt, warum.


Kategorie
Die AI-Welt
Artikel teilen
Jeder wichtige LLM-Benchmark testet auf dieselbe Weise: ein Prompt rein, eine Antwort raus. Sauber, kontrolliert, vollständig spezifiziert. Das Problem ist, dass fast keine KI-Anwendung in der Praxis so funktioniert. Enterprise-KI-Agents führen mehrstufige Unterhaltungen. Sie sammeln Anforderungen über mehrere Nachrichten hinweg, rufen Tools auf, verarbeiten Zwischenergebnisse und führen Informationen zusammen, die erst nach und nach über Dutzende von Interaktionen hinweg offengelegt werden.
Das herausragende Paper der ICLR 2026, LLMs Get Lost In Multi-Turn Conversation, hat untersucht, was passiert, wenn man LLMs so evaluiert, wie Agents sie tatsächlich nutzen. Das Ergebnis: ein durchschnittlicher Genauigkeitsverlust von 39 % über alle getesteten Modelle hinweg.
Das Experiment
Die Forscher Philippe Laban, Hiroaki Hayashi, Yingbo Zhou und Jennifer Neville entwickelten ein Framework, um Standard-Single-Turn-Benchmarks in mehrstufige Unterhaltungen (Multi-Turn) umzuwandeln. Sie nahmen vollständig spezifizierte Anweisungen, zerlegten sie in atomare Informationseinheiten (sogenannte „Shards“) und nutzten einen LLM-basierten Simulator, um pro Interaktion jeweils ein Informationsfragment im natürlichen Gesprächsfluss preiszugeben.
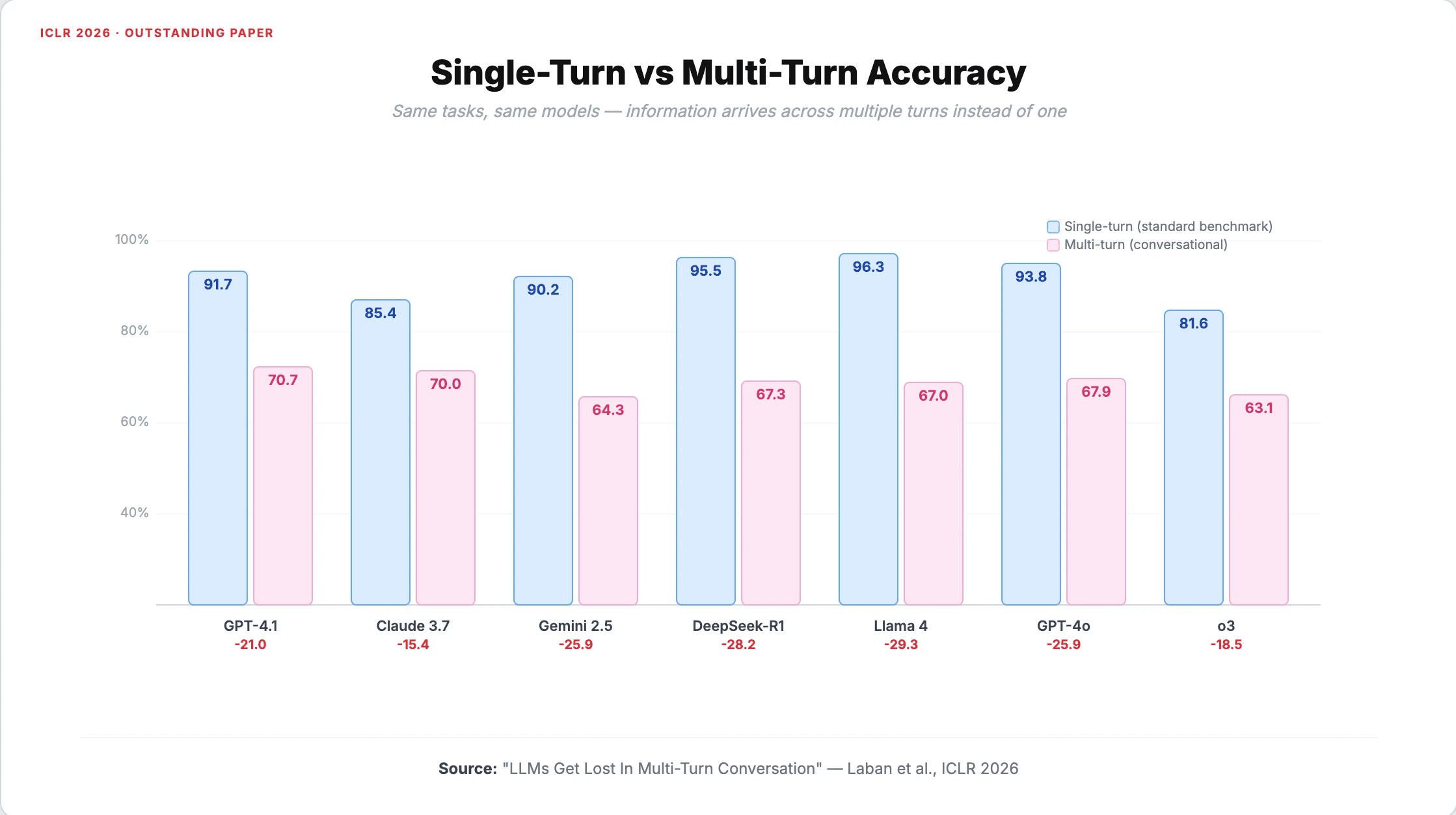
Der Umfang war beträchtlich: Über 200.000 simulierte Unterhaltungen mit 15 Modellen von acht Anbietern, darunter GPT-4.1, Claude 3.7 Sonnet, Gemini 2.5 Pro, DeepSeek-R1 und Llama 4-Scout. Sechs Aufgabentypen deckten Coding, SQL-Abfragen, Funktionsaufrufe, Mathematik, Data-to-Text-Generierung und die Zusammenfassung mehrerer Dokumente ab.
Die Ergebnisse waren eindeutig. GPT-4.1 fiel von 91,7 % auf 70,7 %. Claude 3.7 Sonnet sank von 85,4 % auf 70,0 %. Gemini 2.5 Pro stürzte von 90,2 % auf 64,3 % ab. Größere, leistungsfähigere Modelle zeigten keinen nennenswerten Vorteil bei der Abwehr dieses Leistungsabfalls. Der Einbruch war struktureller Natur und kein Defizit der Modellkapazität.
Ein wichtiges Kontrollexperiment schloss die naheliegende Erklärung aus. Wenn dieselben Informationen in einer einzigen Nachricht zusammengefasst wurden, anstatt sie auf mehrere Interaktionen aufzuteilen, erholte sich die Leistung auf 95 % des Single-Turn-Ausgangswerts. Die Information an sich war also nicht das Problem, sondern das Interaktionsmuster der mehrstufigen Unterhaltung.
Der Zusammenbruch der Zuverlässigkeit ist schlimmer als der Genauigkeitsverlust
Die Schlagzeile unterbewertet das eigentliche Problem. Die Forscher zerlegten die Leistung in zwei Komponenten: Eignung (Aptitude – wie gut das Modell im Durchschnitt abschneidet) und Zuverlässigkeit (Reliability – wie konsistent diese Leistung ist).
Die Eignung sank um 16 %. Die Zuverlässigkeit brach um 112 % ein.
Dieser Unterschied ist für jeden, der KI-Agents in der Produktion einsetzt, von enormer Bedeutung. Mehrstufige Unterhaltungen machen Modelle nicht nur im Durchschnitt etwas schlechter. Sie machen sie extrem inkonsistent. Derselbe Agent, der dieselbe Aufgabe ausführt, kann einmal hervorragende Ergebnisse liefern und beim nächsten Mal völlig scheitern. Die Kluft zwischen dem 90. und dem 10. Perzentil der Leistung betrug in Multi-Turn-Szenarien im Durchschnitt rund 50 Prozentpunkte.
Für den Unternehmenseinsatz, bei dem Vorhersehbarkeit wichtiger ist als Spitzenleistung, ist dies die weitaus gefährlichere Erkenntnis.
Vier Arten, wie LLMs im Gespräch scheitern
Das Paper identifizierte vier unterschiedliche Fehlermuster, die sich jeweils direkt auf das Verhalten von Agents in der Produktion auswirken.
1. Vorzeitige Antwortversuche. Modelle generieren bereits in den ersten 20 % eines Gesprächs vollständige Antworten, wenn ihnen nur minimale Informationen vorliegen. Die Genauigkeit bei vorzeitigen Versuchen lag bei 30,9 %, verglichen mit 64,4 %, wenn die Modelle auf mehr Kontext warteten. In Agent-Workflows äußert sich dies darin, dass das System Entscheidungen trifft, bevor es genügend Informationen gesammelt hat, und dann selbstbewusst auf falschen Annahmen aufbaut.
2. Aufblähen der Antworten (Answer Bloat). Die Länge der Antworten explodiert im Laufe des Gesprächs. Code-Ausgaben sprangen von etwa 700 auf 1.400 Zeichen. Die Modelle bauen auf ihren früheren (oft fehlerhaften) Ausgaben auf, anstatt neu anzusetzen. Kürzere Antworten übertrafen längere Antworten bei fünf von sechs Aufgaben um 10 bis 50 %. Bei Agents verschlechtert sich die Ausgabe im Verlauf der Unterhaltung, da das Modell Korrekturen über Fehler legt, anstatt die Aufgabe noch einmal von Grund auf neu zu überdenken.
3. Der „Lost-in-the-Middle“-Effekt. Modelle berücksichtigen Informationen aus den ersten und letzten Interaktionen überproportional stark. Zitate aus den mittleren Interaktionen fielen unter 20 %. Bei Agents, die über viele Schritte hinweg Anforderungen sammeln, APIs aufrufen und Ergebnisse verarbeiten, wird kritischer Kontext, der in der Mitte eines Workflows auftaucht, praktisch ignoriert.
4. Fehlerfortpflanzung ohne Korrekturmethode. Sobald sich ein Modell früh in einem Gespräch auf eine falsche Annahme festlegt, korrigiert es sich nicht selbst. Die Forscher beschreiben es unmissverständlich: „Wenn LLMs in einem Gespräch falsch abbiegen, verlaufen sie sich und finden nicht wieder zurück.“ Ein falscher Schritt zu Beginn eines mehrstufigen Workflows setzt sich in jedem folgenden Schritt fort, und der Agent wird nicht darauf hinweisen, dass etwas schiefgelaufen ist.
Dieses letzte Fehlermuster entspricht genau dem, was Produktionsteams als geräuschloses Scheitern (Silent Failure) bezeichnen: Ein Agent liefert eine selbstbewusste, formal korrekte, aber inhaltlich völlig falsche Ausgabe, die eine oberflächliche Prüfung problemlos besteht.
Warum Benchmarks Einkäufer von KI-Agents in die Irre führen
Das Paper quantifiziert eine Diskrepanz, die B2B-Entscheider beim Einkauf von KI zwar spüren, aber oft nur schwer in Worte fassen können. Ein LLM erreicht 92 % bei HumanEval. Dasselbe Modell fällt bei derselben Coding-Aufgabe in einer mehrstufigen Unterhaltung, in der Anforderungen schrittweise eintreffen (so wie ein echter Nutzer oder ein System damit interagiert), auf knapp über 70 %.
Single-Turn-Benchmarks testen ein Szenario, das in der Produktion fast nie vorkommt. Enterprise-Agents müssen mit Unschärfen umgehen, Informationen über mehrere Runden hinweg sammeln, externe Tools aufrufen und Teilergebnisse zusammenführen. Jede Interaktion sorgt für mehr Gesprächsrunden. Jede Runde birgt ein Risiko.
Deshalb scheitert die Modellauswahl, die ausschließlich auf Benchmark-Leaderboards basiert. Das Modell, das ein Single-Turn-Leaderboard anführt, ist nicht zwingend das Modell, das in einem 15-stufigen Agent-Workflow am besten abschneidet. Die Evaluierung muss den Einsatzbedingungen entsprechen – und für die meisten Enterprise-Anwendungsfälle bedeutet das Multi-Turn-Unterhaltungen.
Was man dagegen tun kann
Das Paper untersuchte zwei Linderungsstrategien. Ein „Recap“-Ansatz, bei dem das Modell alle gesammelten Informationen zusammenfasst, bevor es eine endgültige Antwort generiert, verbesserte GPT-4o-mini von 50,4 % auf 66,5 %. Ein „Snowball“-Ansatz mit Zusammenfassungen auf jeder Gesprächsstufe zeigte bescheidenere Gewinne. Keiner der Ansätze konnte die Lücke zur Single-Turn-Leistung vollständig schließen.
Für Teams, die Agents entwickeln, ergeben sich aus diesen Erkenntnissen mehrere architektonische Entscheidungen.
Kontextkonsolidierung vor der Generierung. Anstatt sich auf den rohen Chatverlauf zu verlassen, sollten Sie den Kontext an Kontrollpunkten komprimieren und zusammenfassen, bevor das Modell aufgefordert wird, Ausgaben zu generieren. Dies geht das „Lost-in-the-Middle“-Problem direkt an und verringert das Risiko einer Fehlerfortpflanzung.
Multi-Modell-Routing nach Aufgabencharakteristika. Einige Aufgaben sind anfälliger für den Leistungsabfall in mehrstufigen Unterhaltungen als andere. Die Studie zeigte, dass Übersetzungsaufgaben, die Satz für Satz bearbeitet werden können, keinerlei Leistungseinbußen aufwiesen. Aufgaben, die eine Zusammenführung von Informationen über mehrere Runden erfordern, brachen dagegen deutlich ein. Das Routing von Teilaufgaben an verschiedene Modelle auf Basis ihrer Multi-Turn-Resistenz liefert zuverlässigere Ergebnisse, als ein einziges Modell für alles zu nutzen.
Evaluierung in Multi-Turn-Szenarien. Wenn Ihr Agent mehrstufige Workflows ausführt, sollte Ihre Testumgebung auch mehrstufige Workflows prüfen. Die Single-Turn-Genauigkeit ist kein verlässlicher Indikator für die Leistung in der Praxis.
Wiederherstellungsmechanismen einbauen. Da sich Modelle nicht selbst korrigieren, wenn sie vom Weg abkommen, benötigen Agents externe Kontrollpunkte, Validierungsschranken und selbstlernende Feedbackschleifen, anstatt sich darauf zu verlassen, dass das Modell eigene Fehler selbst erkennt.
Die Kluft zwischen Training und Praxiseinsatz
Das ICLR-Komitee hat dieses Paper ausgewählt, weil es eine, wie sie es nannten, „dissonante Kluft“ zwischen der Art und Weise, wie LLMs trainiert werden, und ihrer tatsächlichen Nutzung anspricht. Trainingsdaten sind überwiegend im Single-Turn-Format aufgebaut. Die produktive Nutzung erfolgt überwiegend im Multi-Turn-Format. Die Folge dieser Diskrepanz ist ein Genauigkeitsverlust von 39 % und ein Zusammenbruch der Zuverlässigkeit um 112 %.
Für Enterprise-Teams, die KI-Agents evaluieren, ist die Schlussfolgerung eindeutig: Benchmark-Leistungen zeigen Ihnen, was ein Modell unter idealen Bedingungen leisten kann. Eine Multi-Turn-Evaluierung zeigt Ihnen, was es tatsächlich unter Ihren Bedingungen leisten wird.




