6 min read
Scaling Prompt Tuning Across Domains: How Clustering Unlocked Higher Accuracy With Less Effort

Category
AI Agents
Share the article
Every team building LLM-powered tools eventually faces a crossroads: the system that works beautifully for one domain starts to break down when you ask it to handle several at once.
Our auto-tuner — the engine behind Beam's prompt optimization — has been delivering up to 98% accuracy for single-domain tools. But as our users started building broader agents, the single-domain approach stopped being enough.
The Shift: From Task Agents to Job Agents
Early on, users built narrow agents — one tool per task. A date parser. A name extractor. A schema validator. Each tool had a clearly scoped problem, and feedback from users naturally clustered around a single domain.
Then users started building broader. Instead of five agents each owning a task, they'd build one agent that owns an entire job function — invoice processing, compliance review, onboarding coordination. A single tool handling multiple document types, multiple formatting conventions, multiple success criteria.
This is a natural evolution. LLMs are capable enough now that a single well-crafted prompt can handle what used to require a pipeline of narrow specialists.
The problem: our tuner was optimizing these multi-domain tools as if all feedback belonged to a single problem space.
Why Multi-Domain Feedback Breaks Single-Domain Tuning
When feedback from different domains gets mixed together, three things go wrong:
Conflicting optimization signals. A date formatting fix for invoices and a date formatting fix for compliance documents might require completely different solutions. Averaged together, they produce a compromise that fully solves neither.
Invisible regressions. The tuner improves overall accuracy, but performance in one domain quietly degrades. The aggregate metric looks fine. Individual domain performance does not.
Diminishing returns on effort. Without domain awareness, each optimization cycle has to process every piece of feedback simultaneously. Progress is slow, and the system can't prioritize the domains that need the most work.
With single-domain tools, our tuner reached its accuracy targets efficiently. With multi-domain tools, it could still get there — but it took more cycles and produced less stable results. There had to be a better approach.
The Insight: Cluster First, Then Tune
The breakthrough was recognizing that multi-domain feedback isn't harder to optimize — it's harder to organize. Once feedback is properly organized by domain, each individual tuning problem is no harder than the single-domain case.
We introduced a clustering layer that sits between feedback collection and optimization. Before the tuner ever sees a piece of feedback, the clustering layer groups it by domain — invoice processing, compliance docs, onboarding forms — and generates a label that describes what each cluster represents.
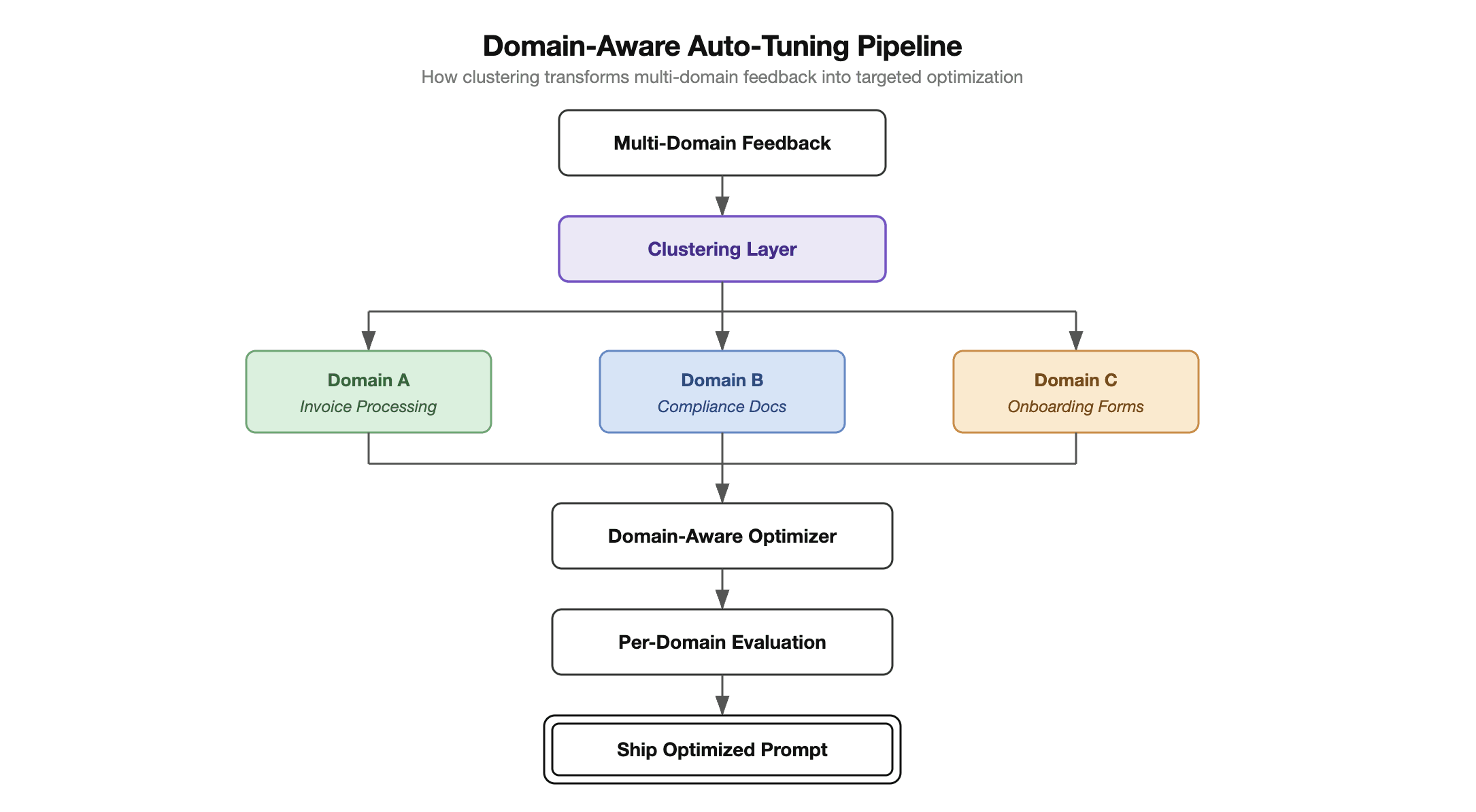
This sounds straightforward. The hard problems are in the details.
Challenge 1: Ensuring High-Quality Cluster Labels
With single-domain tools, categories are predictable. With multi-domain tools built by different teams for different purposes, domains are whatever the user's job description requires — and they change as workflows evolve.
This means cluster labels can't be predefined. They have to be generated dynamically. And dynamically generated labels introduce a new failure mode: a label that sounds right but doesn't actually capture what the feedback has in common.
Our approach treats labeling as an iterative refinement process rather than a one-shot classification. When new feedback arrives, the system generates candidate labels, checks them against existing clusters for coherence, and refines them when the coherence score falls below threshold.
The key principle: a cluster label is a contract with the optimizer. It promises that "all feedback in this group shares the same root cause." We validate this contract continuously. When the optimizer's improvements for a cluster don't correlate with actual accuracy gains in that domain, it's a signal that the label needs refinement.
This creates a self-correcting cycle: the optimizer's results feed back into labeling quality, which improves the optimizer's inputs on the next cycle.
Challenge 2: Domain-Aware Training and Validation
Clustering doesn't just organize feedback — it fundamentally changes how training and validation work.
Training With Domain Context
In the previous pipeline, the optimizer received all feedback at once and produced a single set of prompt improvements. With clustering, training operates with domain awareness at every stage:
Targeted analysis. Each cluster generates its own root cause analysis. Instead of "users are unhappy with output quality," the system identifies "invoice processing feedback shows consistent failures on multi-line items with partial quantities."
Prioritized optimization. The system allocates optimization effort proportionally. A cluster with 50 feedback items and declining accuracy gets more cycles than a stable cluster with 5 items.
Consolidated improvements. After analyzing each cluster independently, the system synthesizes improvements into a unified prompt that handles all domains. The output is one prompt, not many — but it's been built with full awareness of each domain's requirements.
Validation That Catches What Aggregates Miss
Consider this scenario: an optimization cycle improves aggregate accuracy from 91% to 94%. But invoice processing drops from 96% to 88%, masked by gains in the other domains.
Without clustering, an optimizer might see the aggregate improvement and ship. With clustering, the system sees the invoice processing regression immediately and blocks the update.
More importantly, the system tracks what kind of failures occur per domain across optimization cycles. If invoice processing consistently struggles with the same edge case across multiple cycles, that pattern surfaces as a signal — not as noise buried in aggregate metrics.
The validation pipeline evaluates every optimization against each domain independently. The prompt only ships when every domain meets its accuracy threshold.
The Results
We benchmarked the domain-aware pipeline against our previous approach across multi-domain AI agents handling three or more distinct document types.
Three things stood out:
Higher accuracy ceiling. The clustered pipeline consistently reaches 98%+ on multi-domain tools — the same accuracy we were hitting on single-domain tools. The previous approach plateaued around 89–91%.
Dramatically fewer optimization cycles. Because each cycle targets specific domains with specific issues, progress is faster. Multi-domain tools now converge in roughly the same number of cycles as single-domain tools used to.
Regressions became visible and preventable. Cross-domain regressions went from being discovered in production to being caught and blocked during validation. This was the biggest operational win.
What This Means for Beam Users
For teams building on Beam, this is largely invisible — which is the point. Your multi-domain agents simply tune better, converge faster, and don't regress silently.
Build broader agents confidently. The tuner now handles the complexity of multi-domain optimization, so you don't have to architect around it. One agent that owns an entire job function is no harder to tune than a narrow single-task tool.
Trust the accuracy across all your domains. Per-domain validation means the tuner won't sacrifice one part of your workflow to improve another. Every domain has to pass before an optimization ships.
Expect faster convergence. With structured, domain-aware optimization, the tuner reaches its accuracy targets in fewer cycles. Less time tuning means more time shipping.
The evolution from single-domain to multi-domain tuning wasn't about making the optimizer smarter. It was about giving the optimizer better-organized information to work with.
As agents continue to grow in scope — handling more domains, more document types, more edge cases — the ability to tune across domains without regressions isn't a nice-to-have. It's the foundation that makes broader agents viable in production.




