

Category
AI Agents
Share the article
Gartner reported a 1,445% surge in multi-agent system inquiries between Q1 2024 and Q2 2025. Organizations already use an average of 12 agents, and that number is projected to climb 67% within two years.
But 40% of multi-agent pilots fail within six months of production deployment. The pattern isn't that multi-agent systems don't work. It's that teams pick the wrong orchestration pattern for their problem, or they pick the right one without understanding how it breaks.
Here are six patterns that hold up in production, along with the specific ways each one fails when it doesn't.
1. Orchestrator-worker
One agent receives the task, breaks it into subtasks, delegates each to a specialist worker, and assembles the results. The orchestrator uses a capable model while workers use cheaper, task-specific ones, cutting costs 40-60%.
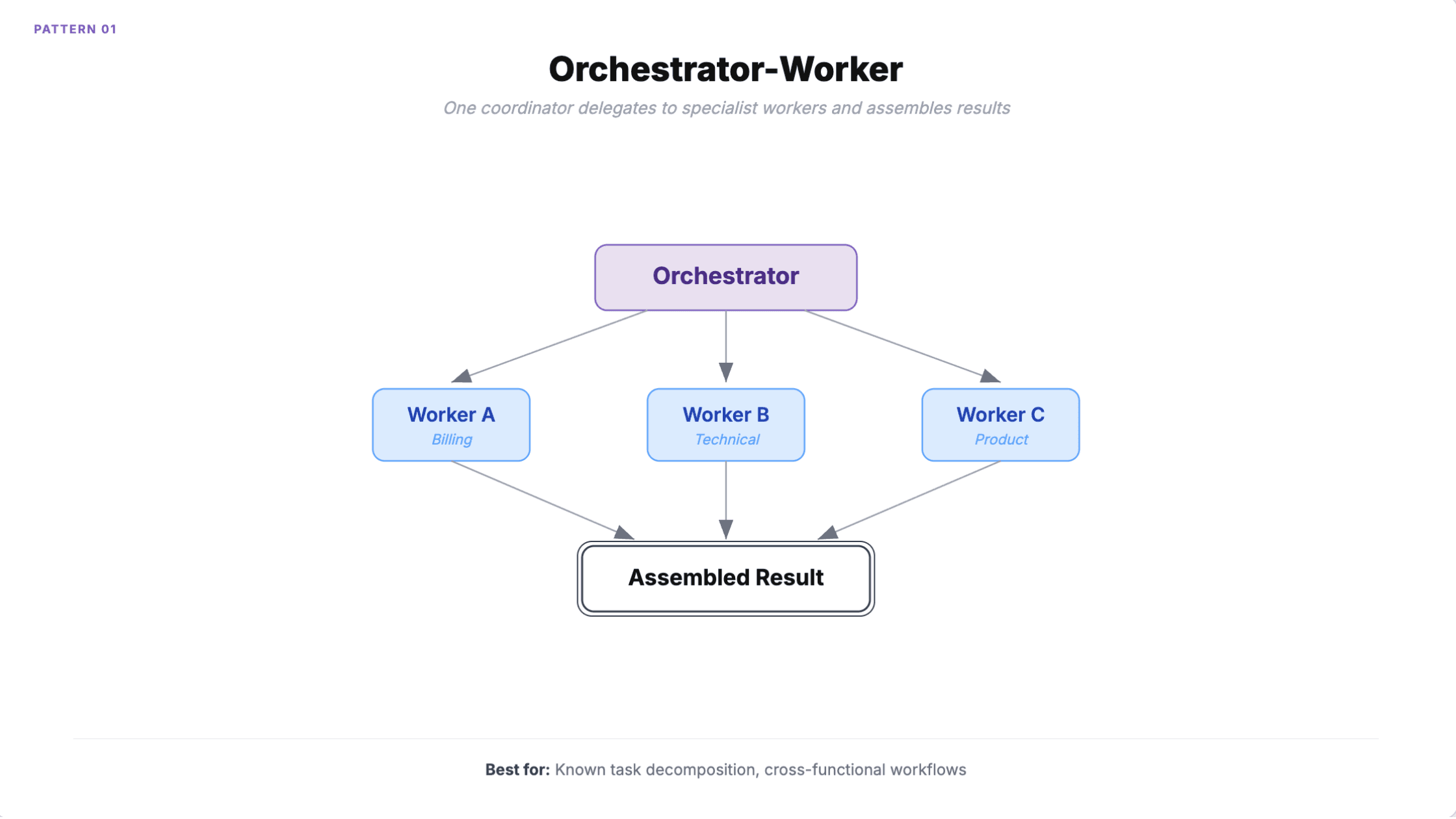
When to use it: Cross-functional workflows with clear task decomposition. Customer service routing between billing, technical, and product specialists. Any job where you need a single accountability point.
Wells Fargo uses this pattern to give 35,000 bankers access to 1,700 procedures in 30 seconds, down from 10 minutes. Salesforce's Agentforce 2.0 implements it through their Atlas Reasoning Engine.
How it fails
The orchestrator is a single point of failure. If it misclassifies a task, the wrong worker gets it, and misclassification rates compound at scale.
Context window overflow is the more subtle problem. The orchestrator accumulates context from every worker. At four or more workers, context frequently exceeds window limits. Workflows that cost $0.50 in testing can hit $50,000/month at 100K executions because the orchestrator makes multiple LLM calls for decomposition and aggregation on top of every worker call.
2. Sequential pipeline
Agents execute in a predefined linear chain. Each one processes the previous agent's output through shared state. The order is deterministic, defined at design time.
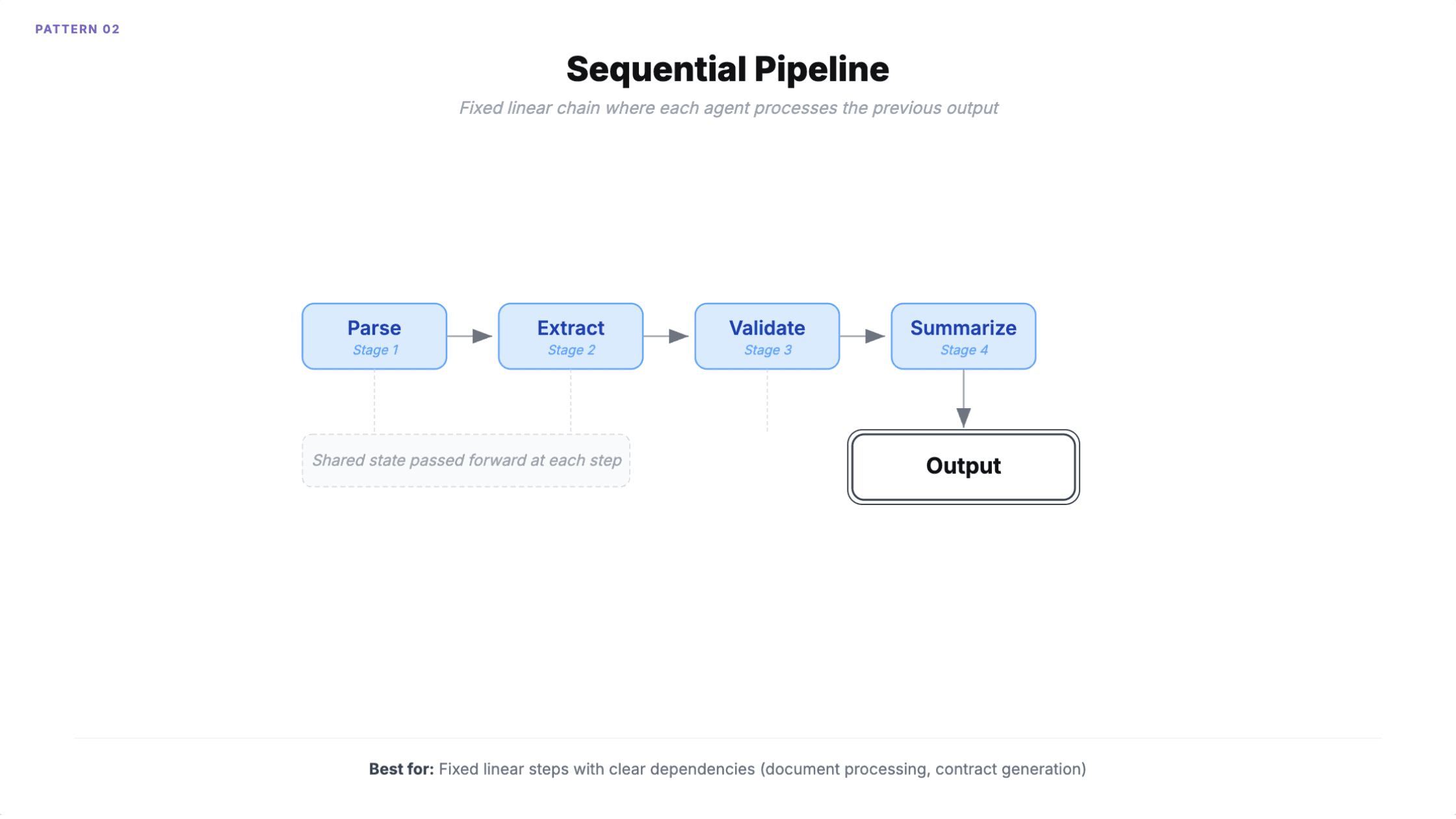
When to use it: Document processing (parse, extract, validate, summarize). Contract generation. Content moderation. Any multi-stage process with clear linear dependencies.
Microsoft's Azure Architecture Center documents a law firm using this for contract generation: template selection, clause customization, compliance review, and risk assessment, each handled by a separate AI agent.
How it fails
Error propagation. Bad output in stage 1 cascades through every downstream stage with no backtracking.
The less obvious problem is overhead. A four-agent pipeline accumulates roughly 950ms of coordination overhead while actual processing takes 500ms. A three-agent pipeline consumes 29,000 tokens versus 10,000 for an equivalent single-agent approach. If your pipeline doesn't need the specialization, you're paying 3x for the same result.
3. Fan-out / fan-in
Multiple agents execute simultaneously on the same input or on independent subtasks. A dispatcher sends work out, a collector aggregates results using voting, weighted merging, or LLM-based synthesis.
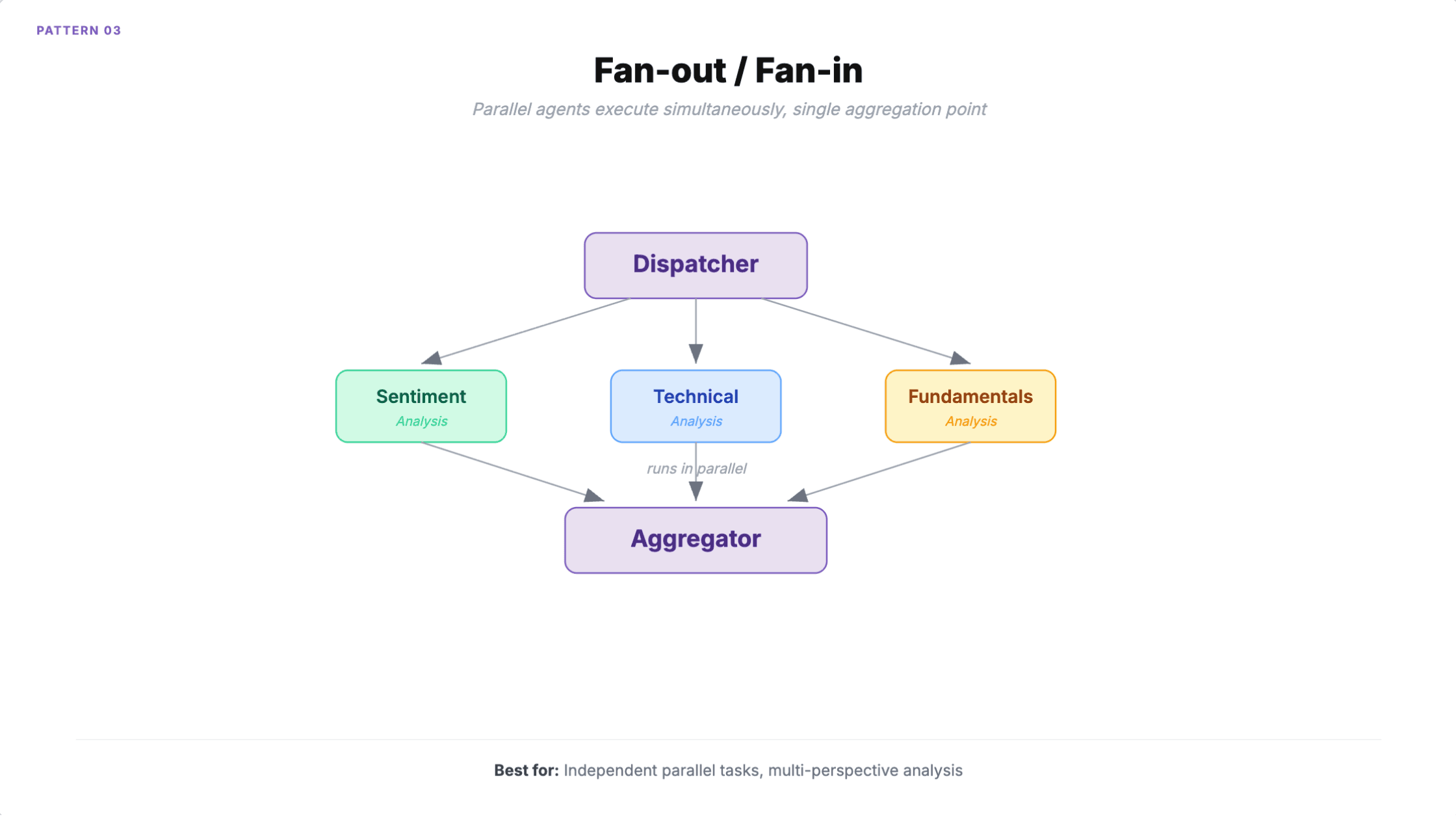
When to use it: Multi-perspective analysis (financial analysis with fundamental, technical, sentiment, and ESG agents running in parallel). Concurrent code review across security, style, and performance. Any scenario with four or more independent tasks where you need to cut wall-clock time by 75%.
How it fails
API rate limits. Fifteen concurrent agents consuming 150 requests per second when your limit is 100. Each agent is within limits individually, but the collective load exceeds capacity.
Race conditions on shared state scale quadratically. A system with N agents has N(N-1)/2 potential concurrent interactions. At five agents that's 10 potential conflicts. At ten it's 45.
The aggregation step itself introduces error. LLM-based synthesis can hallucinate consensus that doesn't exist in the underlying results. If your parallel agents disagree (sentiment says buy, fundamentals says sell), you need an explicit conflict resolution strategy, not just "summarize the results."
4. Multi-agent debate
Multiple agents participate in a shared conversation, contributing perspectives, challenging each other, and refining positions across rounds. Includes maker-checker loops where one agent generates and another validates until approved.
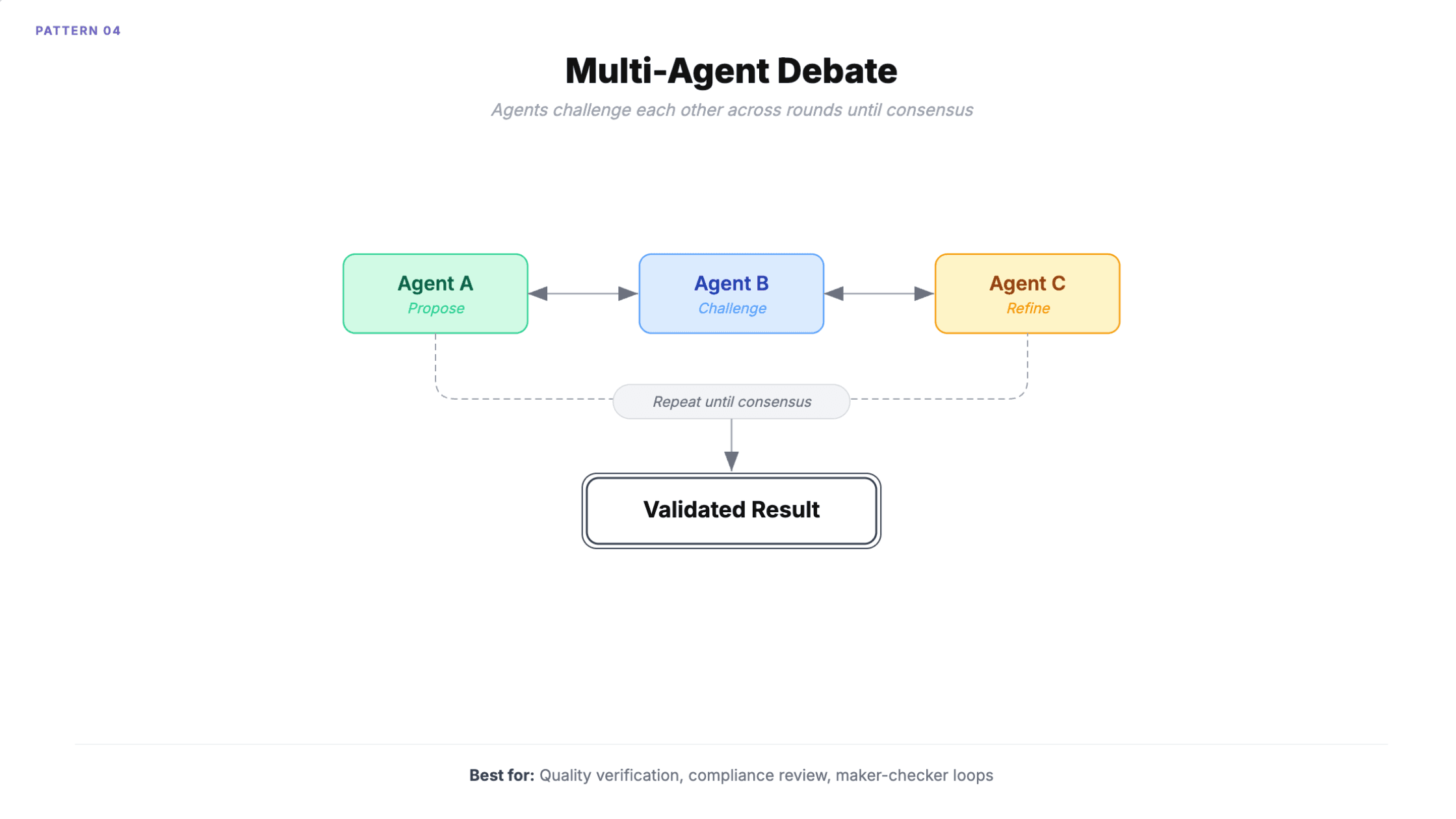
When to use it: Compliance review requiring multiple expert perspectives. Quality assurance with structured review. Research shows debate reduces hallucinations compared to single-model queries because agents catch each other's mistakes.
A practical variant: use a cheap fast model for the maker and a capable model for the checker. You get the quality improvement of debate at 40-60% lower cost than running both on capable models.
How it fails
Conversation loops. Agents keep debating without converging. Microsoft recommends limiting group chat to three or fewer agents for this reason.
Sycophancy cascading is the harder problem. Agents tend to agree with the majority position even when wrong, producing false consensus. Five rounds with three agents means 15 LLM calls per task, and the result can still be confidently incorrect because the agents reinforced each other's errors.
5. Dynamic handoff
Each agent assesses the current task and decides whether to handle it or transfer control to a more appropriate specialist. Unlike orchestrator-worker, there's no central coordinator. Agents delegate to each other based on runtime context. Only one agent is active at a time.
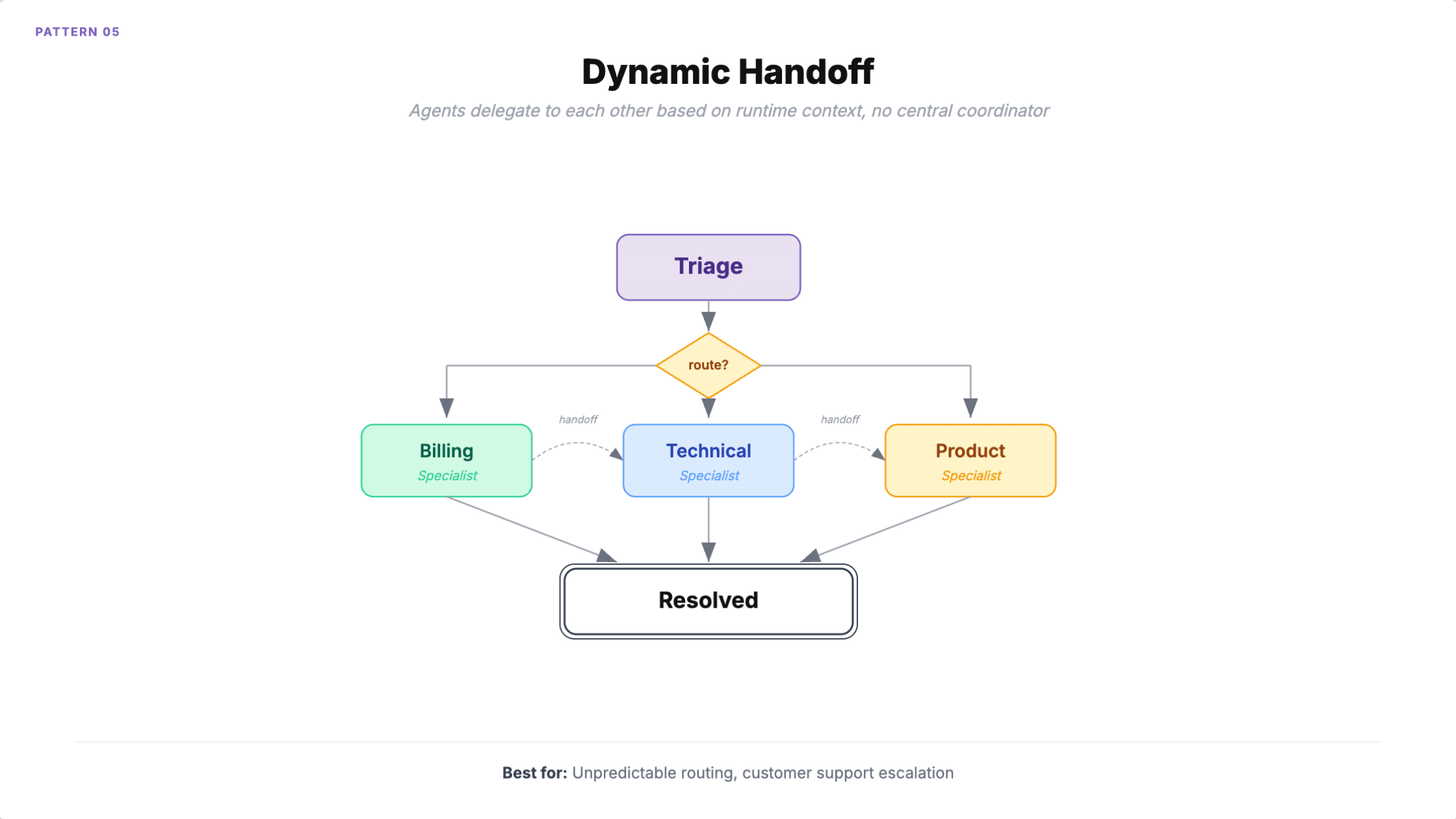
When to use it: Customer support where the right specialist emerges during conversation (a billing issue reveals it's actually a technical problem). Tasks where expertise requirements aren't known upfront.
HCLTech reported 40% faster case resolution through dynamic agent handoff. The pattern works well when you genuinely cannot predict which specialist an interaction will need at the start.
How it fails
Infinite handoff loops. Agent A passes to B, B passes to C, C passes back to A. This is the number one failure mode. Each agent keeps replanning because nobody owns the task.
Context loss compounds with every transfer. Either you pass full context (expensive and eventually exceeds windows) or you summarize (lossy, and accumulated summarization errors degrade quality). And because routing is non-deterministic, the same input can produce wildly different agent chains, making debugging nearly impossible.
6. Adaptive planning
A manager agent dynamically builds, refines, and executes a task plan by consulting specialists. Unlike orchestrator-worker where the plan is known upfront, here the plan itself is discovered through collaboration. The manager iterates, backtracks, and delegates as needed, continuously checking whether the original goal is met.
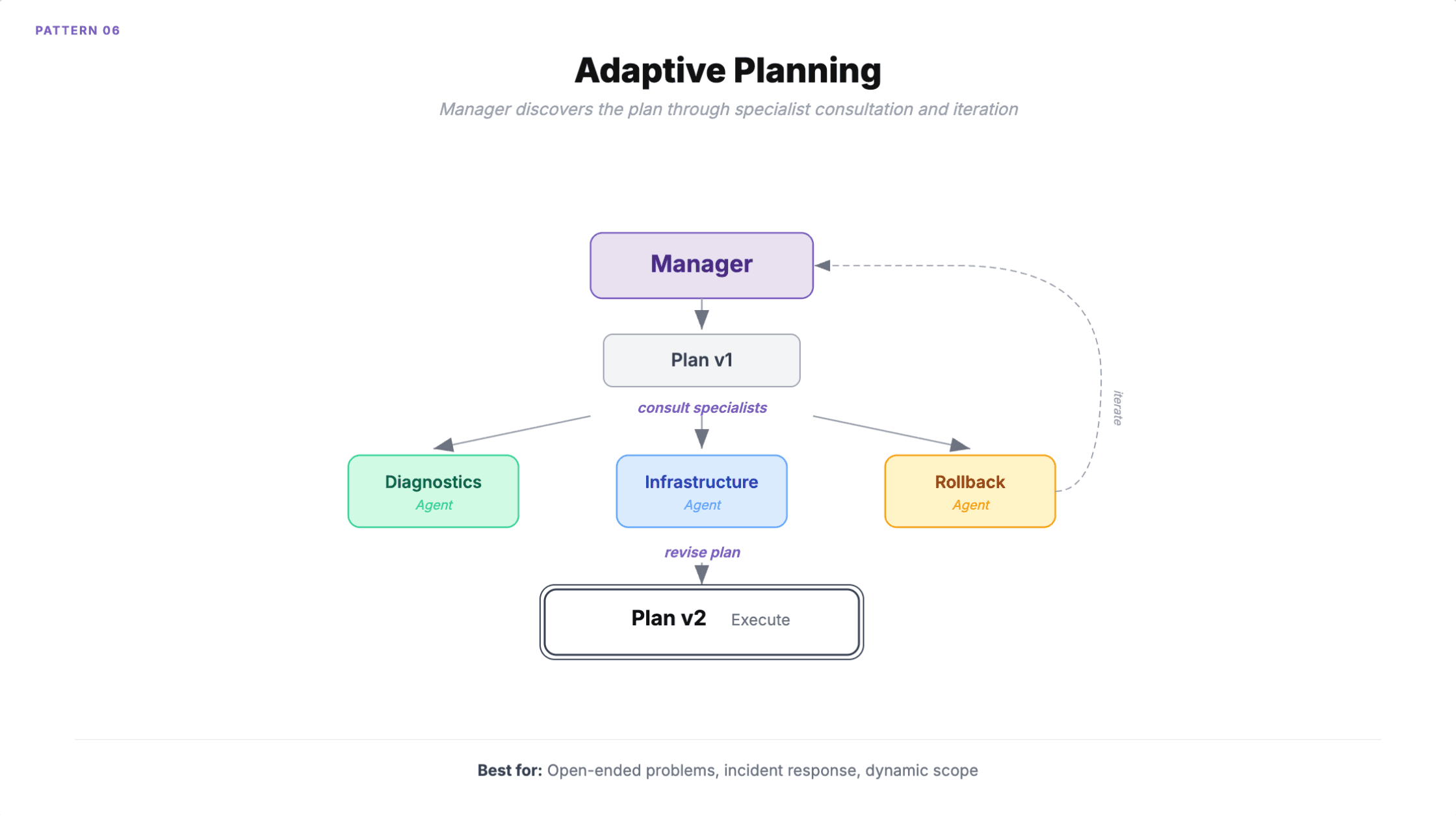
When to use it: Open-ended problems with no predetermined solution path. Incident response where remediation steps emerge from diagnosis. Complex migrations where scope changes during execution.
Microsoft documents an SRE example: the manager creates an initial plan, consults diagnostic and infrastructure agents, and when diagnostics reveals a database issue instead of a deployment problem, the entire plan pivots in real time.
How it fails
Slow to converge. The pattern optimizes for correctness over speed. Time-sensitive tasks are poor fits.
Goal drift is the production killer. Over multiple iterations, the manager's refined plan can diverge significantly from the original intent. Backtracking makes it worse: when the manager discovers a dead end, all work from that branch is wasted compute, and the cost is impossible to predict upfront. If the original request is vague, the manager can loop indefinitely trying to build a "complete" plan that satisfies an underspecified goal.
How to pick the right pattern
Start with the simplest pattern that fits your problem. Most teams over-architect.
Known task decomposition? Orchestrator-worker. You know the subtasks at design time and want a single accountability point.
Fixed linear steps? Sequential pipeline. The order never changes and each step depends on the previous output.
Independent parallel work? Fan-out/fan-in. Four or more tasks with no dependencies between them.
Need quality verification? Multi-agent debate. Especially maker-checker loops where accuracy matters more than speed.
Unpredictable routing? Dynamic handoff. You cannot know which specialist is needed until the conversation unfolds.
Open-ended problem? Adaptive planning. The plan itself needs to be discovered, not just executed.
Princeton NLP found that a single agent matched or outperformed multi-agent systems on 64% of benchmarked tasks when given the same tools and context. Multi-agent adds 2.1 percentage points of accuracy at roughly double the cost. That tradeoff is worth it for complex cross-domain work. For everything else, a well-built single AI agent is simpler, faster, and cheaper.
The best orchestration pattern is the one that matches your actual problem, not the most sophisticated one you can build.




