6 min read
Your AI Agent Loses 39% Accuracy in Real Conversations. ICLR 2026's Outstanding Paper Explains Why.


Category
The AI World
Share the article
Every major LLM benchmark tests the same way: one prompt in, one answer out. Clean, controlled, fully specified. The problem is that almost no real-world AI application works like that. Enterprise AI agents run multi-turn conversations. They collect requirements across messages, call tools, process intermediate results, and synthesize information revealed piece by piece over dozens of turns.
ICLR 2026's outstanding paper, LLMs Get Lost In Multi-Turn Conversation, tested what happens when you evaluate LLMs the way agents actually use them. The answer: a 39% average accuracy drop across every model tested.
The experiment
Researchers Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville developed a framework to convert standard single-turn benchmarks into multi-turn conversations. They took fully specified instructions, split them into atomic pieces of information called "shards," and used an LLM-based simulator to reveal one piece per turn in natural conversational flow.
The scale was substantial: over 200,000 simulated conversations across 15 models from eight providers, including GPT-4.1, Claude 3.7 Sonnet, Gemini 2.5 Pro, DeepSeek-R1, and Llama 4-Scout. Six task types covered coding, SQL queries, function calling, math, data-to-text generation, and multi-document summarization.
The results were consistent. GPT-4.1 dropped from 91.7% to 70.7%. Claude 3.7 Sonnet fell from 85.4% to 70.0%. Gemini 2.5 Pro went from 90.2% to 64.3%. Larger, more capable models showed no meaningful advantage in resisting the degradation. The drop was structural, not a capability gap.
A critical control experiment ruled out the obvious explanation. When the same information was concatenated into a single message rather than split across turns, performance recovered to 95% of the single-turn baseline. The information itself was not the problem. The multi-turn interaction pattern was.
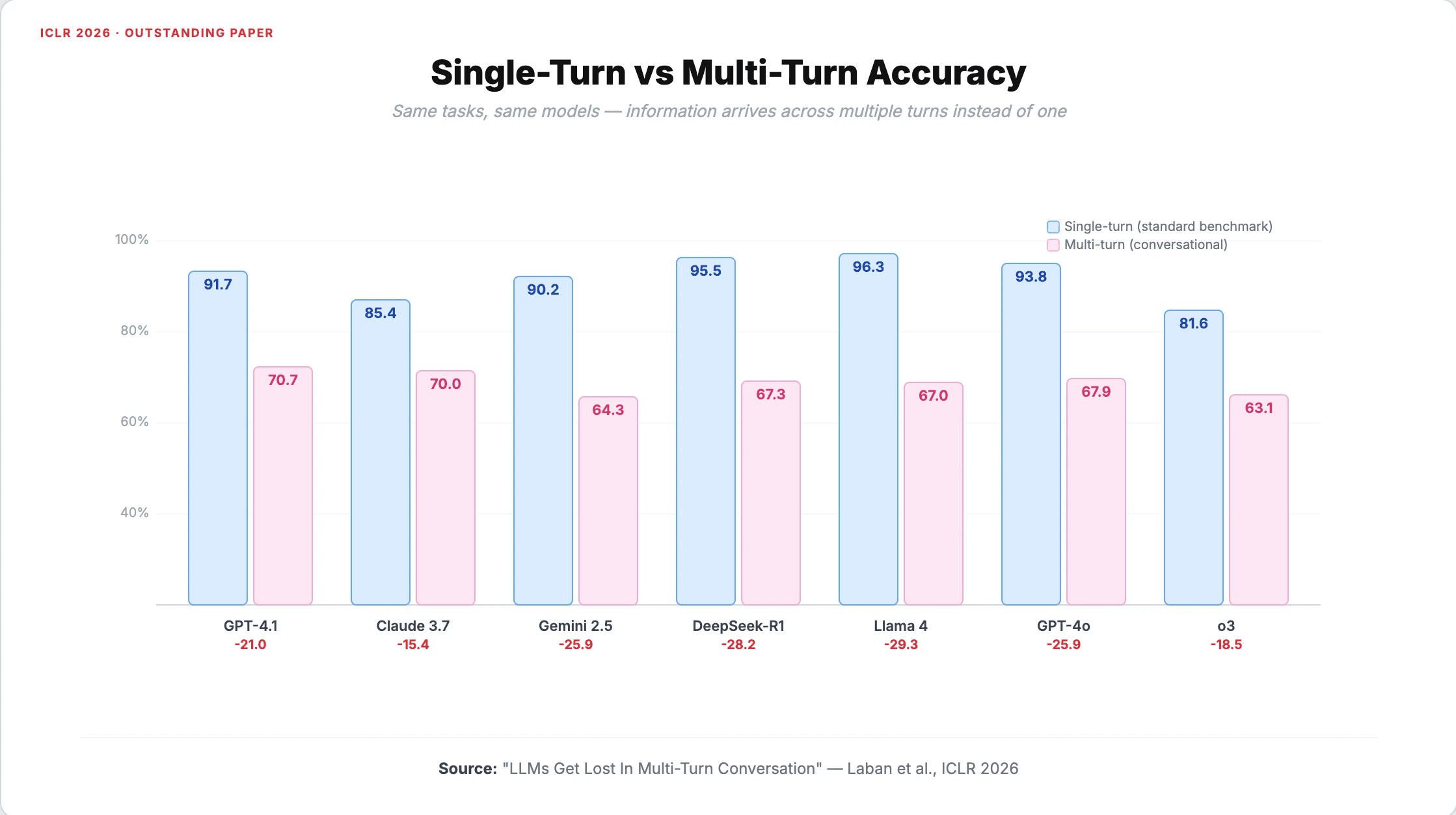
The reliability collapse is worse than the accuracy drop
The headline number understates the real issue. The researchers decomposed performance into two components: aptitude (how well the model performs on average) and reliability (how consistent that performance is).
Aptitude dropped by 16%. Reliability collapsed by 112%.
That distinction matters enormously for anyone running production AI agents. Multi-turn conversations do not just make models slightly worse on average. They make models wildly inconsistent. The same agent doing the same task might succeed brilliantly once and fail completely the next time. The gap between 90th and 10th percentile performance averaged roughly 50 percentage points in multi-turn settings.
For enterprise deployments where predictability matters more than peak performance, this is the more dangerous finding.
Four ways LLMs fail in conversation
The paper identified four distinct failure modes, each with direct implications for agent behavior in production.
1. Premature answer attempts. Models generate full answers in the first 20% of a conversation when they have minimal information. Accuracy for premature attempts: 30.9%, compared to 64.4% when models waited for more context. In agent workflows, this shows up as the system making decisions before gathering enough information, then building confidently on wrong assumptions.
2. Answer bloat. Response length balloons across turns. Code outputs jumped from roughly 700 to 1,400 characters. Models append to their earlier (often incorrect) outputs rather than starting fresh. Shorter responses outperformed longer ones by 10-50% across five of six tasks. For agents, outputs degrade as conversations progress, with the model layering corrections on top of mistakes instead of reconsidering from scratch.
3. Lost-in-middle effect. Models disproportionately attend to information from the first and last turns. Citations to middle turns dropped below 20%. For agents that collect requirements, call APIs, and process results across many steps, critical context revealed in the middle of a workflow gets effectively ignored.
4. Compounding errors with no recovery. Once a model commits to an incorrect assumption early in a conversation, it does not self-correct. The researchers describe it plainly: "When LLMs take a wrong turn in a conversation, they get lost and do not recover." A wrong step early in a multi-step workflow compounds through every subsequent step, and the agent will not flag that something went wrong.
This last failure mode maps directly to what production teams call silent failure: an agent produces a confident, well-formatted, completely wrong output that passes surface-level review.
Why benchmarks mislead agent buyers
The paper quantifies a gap that enterprise AI buyers have felt but struggled to articulate. An LLM scores 92% on HumanEval. The same model, doing the same coding task in a multi-turn conversation where requirements arrive incrementally (the way a real user or system interacts with it), drops to the low 70s.
Single-turn benchmarks test a scenario that almost never occurs in production. Enterprise agents handle ambiguity, collect information across turns, call external tools, and synthesize partial results. Every interaction adds turns. Every turn adds risk.
This is why model selection based on benchmark leaderboards alone fails. The model that tops a single-turn leaderboard is not necessarily the model that performs best across a 15-turn agent workflow. Evaluation needs to match deployment conditions, and for most enterprise use cases, deployment is multi-turn.
What to do about it
The paper tested two mitigation strategies. A "recap" approach, where the model summarizes all accumulated information before generating a final answer, improved GPT-4o-mini from 50.4% to 66.5%. A "snowball" approach with turn-level recapitulation showed more modest gains. Neither fully closed the gap to single-turn performance.
For teams building agents, several architectural decisions follow from these findings.
Context consolidation before generation. Rather than relying on raw conversation history, compress and summarize context at checkpoints before asking the model to produce outputs. This directly addresses the lost-in-middle problem and reduces the surface area for compounding errors.
Multi-model routing by task characteristics. Some tasks are more vulnerable to multi-turn degradation than others. The paper found that translation tasks, which can be completed sentence by sentence, showed zero degradation. Tasks requiring cross-turn information fusion degraded significantly. Routing subtasks to different models based on their multi-turn resilience produces more reliable outcomes than picking one model for everything.
Evaluate in multi-turn settings. If your agent runs multi-turn workflows, your evaluation suite should test multi-turn workflows. Single-turn accuracy is not a reliable proxy for production performance.
Build recovery mechanisms. Since models do not self-correct when they go off track, agents need external checkpointing, validation gates, and self-learning feedback loops rather than relying on the model to catch its own mistakes.
The gap between training and deployment
The ICLR committee selected this paper because it addresses what they called a "dissonant gap" between how LLMs are trained and how they are deployed. Training data is predominantly single-turn. Production usage is predominantly multi-turn. The gap between those two settings is a 39% accuracy drop and a 112% reliability collapse.
For enterprise teams evaluating AI agents, the implication is straightforward: benchmark performance tells you what a model can do under ideal conditions. Multi-turn evaluation tells you what it will actually do in yours.




