1 Min. Lesezeit
Was ist kontinuierliches Lernen? (Und warum es selbstlernende KI-Agenten antreibt)


Kategorie
Agentische Automatisierung
Artikel teilen
KI-Modelle fühlen sich intelligent an, bis sich die Welt verändert.
Ein Kundenbetreuer gibt nach einem Produkt-Update veraltete Antworten aus.
Ein Finanz-Workflow-Bot verpasst neue Richtlinien, die letzten Monat eingeführt wurden.
Ein Recruiting-Assistent vergisst die Einstellungsrichtlinien des letzten Quartals, sobald Sie ihm die des aktuellen Quartals beibringen.
Dies sind keine Randfälle. Sie kommen vor, wenn KI wie ein statisches Artefakt in einem dynamischen Unternehmen behandelt wird.
Kontinuierliches Lernen ist der Weg weg von diesem Ansatz. Es ist die Idee, dass Modelle nach der Bereitstellung weiterhin lernen sollten, ohne das zu verlieren, was bereits funktioniert. Die große Frage ist: Kann KI neues Wissen hinzufügen, ohne altes Wissen zu löschen? Forscher nennen das Versagensmuster katastrophisches Vergessen.
Bei Beam steht dieses Problem im Mittelpunkt unserer Vision von selbstlernenden KI-Agenten, Agenten, die sich im Laufe der Zeit verbessern, während sich Workflows, Daten und Geschäftsregeln weiterentwickeln. Kontinuierliches Lernen ist eine der Forschungssäulen, die dies möglich machen.
Was ist Fortwährendes Lernen?
Fortwährendes Lernen (auch lebenslanges Lernen oder inkrementelles Lernen genannt) ist, wenn ein Modell sein Wissen schrittweise aus neuen, sich ändernden Daten aktualisiert, ohne von Grund auf neu trainiert zu werden und ohne ältere Fähigkeiten zu vergessen.
Zwei Bedingungen definieren es:
Nicht-stationäre Daten
Die Datenverteilung verschiebt sich im Laufe der Zeit. Neue Sonderfälle treten auf. Nutzerverhalten ändert sich. Richtlinien entwickeln sich.
Inkrementelle Updates
Das Modell lernt in einer Abfolge von Updates, während es weiterhin nutzbar bleibt.
Mit anderen Worten, fortwährendes Lernen ist Lernen in der realen Welt, nicht Lernen in einem eingefrorenen Labordatensatz.
Für Enterprise-AI ist das keine Option. Es ist die Umgebung.
Warum vergessen Modelle? Katastrophales Vergessen erklärt
Wenn Sie ein neuronales Netzwerk auf Aufgabe A trainieren und es dann für Aufgabe B feinabstimmen, bricht die Leistung auf Aufgabe A oft zusammen. Das ist katastrophales Vergessen.
Warum es passiert:
Dieselben Parameter speichern altes und neues Wissen.
Wenn Aufgabe B die Gewichte aktualisiert, entfernen sie sich vom Optimum für Aufgabe A.
Sequenzielles Training verursacht Interferenzen zwischen den Aufgaben.
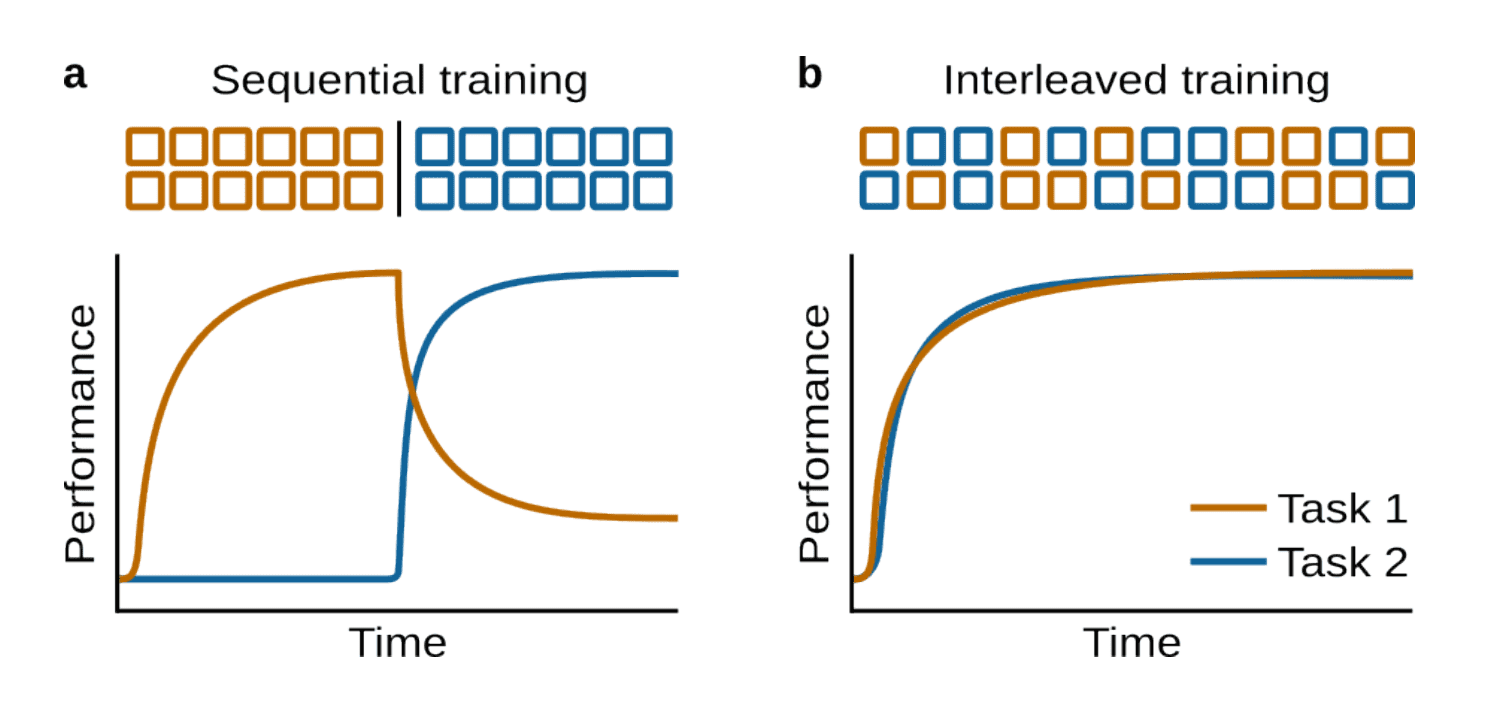
Quelle: Illustration des katastrophalen Vergessens, „Fortwährendes Lernen und Katastrophales Vergessen“ Papier
Beispiel von Beam:
Stellen Sie sich vor, ein Beam-Agent bearbeitet Rechnungsausnahmen. Sie stimmen es auf neue Lieferantenregeln für Q4 ab. Plötzlich scheitert es an älteren Regeln, die immer noch für alte Lieferanten gelten. Der Agent hat „gelernt“, aber nur dadurch, dass funktionierendes Verhalten überschrieben wurde. Das ist Vergessen in einem Produktions-Workflow.
Deshalb ist „es einfach erneut feinabstimmen“ keine echte Strategie für langlebige Agenten.
Fortwährendes Lernen vs Feinabstimmung vs RAG (Warum das für LLMs wichtig ist)
Menschen verwechseln diese oft, also lassen Sie uns sie klar trennen:
Feinabstimmung
Aktualisiert das Modell, aber wenn nicht kontrolliert, besteht die Gefahr, alte Fähigkeiten zu überschreiben. Großartig für einmalige Domänenanpassung, riskant für laufende Updates.
RAG (Retrieval-Augmented Generation)
Fügt frische Informationen zur Inferenzzeit hinzu, indem Dokumente abgerufen werden. Es ist mächtig, ändert aber das Verhalten nicht dauerhaft. Ein Modell kann immer noch eine Woche später dieselben strukturellen Fehler machen.
Fortwährendes Lernen
Fügt dauerhaft neues Wissen hinzu und bewahrt altes Wissen, sodass das Modell tatsächlich im Laufe der Zeit evolvieren kann.
Beam-Fazit:
Moderne AI-Agenten benötigen sowohl Abruf als auch fortwährende Verbesserung. Abruf hält Antworten aktuell. Fortwährendes Lernen hält das Verhalten aktuell.
Das Stabilitäts-<> Plastizitäts-Dilemma
Jedes fortwährende Lernsystem optimiert zwei Kräfte:
Plastizität: schnelle Aufnahme neuer Dinge.
Stabilität: alte Dinge intakt halten.
Zuviel Plastizität → Vergessen.
Zuviel Stabilität → das Modell kann sich nicht anpassen.
Fortwährendes Lernen ist also im Grunde kontrollierte Evolution: lernen, ohne das eigene Gehirn umzuschreiben.
Aufstellungen für Fortwährendes Lernen: Aufgabenbasiert vs Aufgabenfrei
Forscher bewerten fortwährendes Lernen in zwei Hauptaufstellungen:
Aufgabenbasiertes fortwährendes Lernen
Daten kommen in klaren Blöcken (Aufgabe 1 → Aufgabe 2 → Aufgabe 3), und das Modell weiß, wann sich die Grenzen ändern.
Nützlich für die Forschung, weniger realistisch für die Produktion.
Aufgabenfreies fortwährendes Lernen
Daten verändern sich allmählich ohne explizite Grenzen. Das Modell muss erkennen, wann sich die Welt verändert, und sich reibungslos anpassen.
Schwieriger, aber näher an realen Unternehmensströmen.
Beam-Kontext:
Unternehmensagenten sind fast immer aufgabenfrei. HR-Tickets kommen nicht in sauberen Phasen. Lieferantenrichtlinien ändern sich fortlaufend. Kundenabsichten entwickeln sich unvorhersehbar. Methoden des fortwährenden Lernens, die in aufgabenfreien Umgebungen funktionieren, sind diejenigen, die in realen Beam-Einsätzen von Bedeutung sein werden.
Kernmethoden des Fortwährenden Lernens (Der klassische Werkzeugkasten)
Die meisten Ansätze fallen in drei Familien:
1. Wiederholung / Probe
Mischen Sie alte Daten mit neuen Daten während des Trainings, damit das Modell nicht abweicht.
Vorteile: starke Speicherung.
Nachteile: Speicherung alter Daten kann teuer, riskant oder eingeschränkt sein.
2. Regularisierung
Schätzen Sie, welche Gewichte für alte Aufgaben wichtig waren, und bestrafen Sie Änderungen an ihnen. Elastic Weight Consolidation (EWC) ist das bekannteste Beispiel.
Vorteile: keine Notwendigkeit, alte Daten zu speichern.
Nachteile: kann das Lernen über viele Updates hinweg verlangsamen.
3. Parameterisolierung / -expansion
Weisen Sie neuen Aufgaben separate Parameter zu (Adapter, LoRA-Stapel, Experten-Routing).
Vorteile: vermeidet Interferenzen.
Nachteile: Modelle können im Laufe der Zeit wachsen, und das Routing kann komplex werden.
Diese Methoden sind nützlich, aber sie wurden nicht für fortwährendes Lernen im LLM-Maßstab in der Produktion entwickelt. Deshalb erhalten neue Arbeiten von Google und Meta Aufmerksamkeit.
Googles Verschachteltes Lernen: Überdenken, wie Modelle fortwährend lernen
Die Google-Forschung stellte auf der NeurIPS 2025 das Verschachtelte Lernen vor. Die große Behauptung: wir haben Architektur und Optimierung zu lange getrennt, und diese Trennung begrenzt fortwährendes Lernen.
Die Kerngesprächung
Statt ein Modell als einen Lernprozess zu sehen, betrachtet Verschachteltes Lernen es als einen Stapel von Lernproblemen, die ineinander verschachtelt sind, wobei jedes auf unterschiedlichen Zeitskalen arbeitet.
Stellen Sie sich das so vor:
schnell ändernde Teile passen sich an die neuen Daten an,
langsam ändernde Teile bewahren langfristiges Wissen,
und das System lernt wie man sich selbst aktualisiert.
HOPE: das Proof-of-Concept-Modell
Google kombinierte Verschachteltes Lernen mit einer neuen Architektur namens HOPE, die kombiniert:
ein selbstmodifizierendes Sequenzmodell (lernt seine eigene Aktualisierungsregel), und
ein Kontinuum-Gedächtnissystem das über kurzfristige und langfristige Gedächtnis-Splits hinausgeht.
Warum Verschachteltes Lernen wichtig ist
Wenn dies skaliert, weist es auf eine Zukunft hin, in der LLMs nicht nur einen langen Kontext in Aufforderungen halten - sie lernen strukturell in Schichten, alte Fähigkeiten wiedergewinnen während sie neue hinzufügen. Das ist ein bedeutender Fortschritt für ständig aktive Agenten.
Beam-Perspektive:
Verschachteltes Lernen stimmt mit der Richtung überein, in die sich Beam bewegt: Agenten, die sich auf mehreren Ebenen sicher aktualisieren, von einem kurzfristigen Workflow-Kontext bis hin zum langfristigen prozeduralen Wissen, ohne vollständige Modell-Resets zu benötigen.
Metas Sparse Memory Fine-Tuning: Neue Dinge lernen, indem fast nichts aktualisiert wird
Meta FAIRs Oktober 2025 Papier, „Fortwährendes Lernen über Sparse Memory Fine-Tuning“ greift das Vergessensproblem aus der entgegengesetzten Richtung an: nicht alle Parameter aktualisieren, sondern nur ein spärliches, relevantes Gedächtnis.
Die Intuition
Vergessen passiert, weil Aufgaben dieselben Parameter teilen. Also führt Meta eine Gedächtnisschicht mit vielen Gedächtnis-„Slots“ ein. Bei jedem Vorwärtslauf wird nur ein winziger Teil aktiviert.
Wenn neues Wissen ankommt, aktualisiert das Modell nur die Slots, die mit diesem Wissen am meisten verbunden sind.
Wie es auswählt, welches Gedächtnis zu aktualisieren ist
Sie verwenden einen TF-IDF-ähnlichen Score:
TF: wie oft ein Slot durch die neuen Daten aktiviert wird.
IDF: wie selten es während des Vortrainings verwendet wurde.
Slots, die hohe TF, hohe IDF haben, sind „sicher zu aktualisieren“, weil sie relevant für neue Informationen sind, aber für das alte Verhalten nicht wesentlich.
Die Ergebnisse in einer Zeile
In ihren QA-Experimenten zum fortwährenden Lernen:
Volles Fine-Tuning führte zu einem Leistungsverlust von ~89% auf der ursprünglichen Leistung,
LoRA führte zu ~71% Verlust,
sparse memory fine-tuning nur ~11%, während trotzdem neue Fakten gelernt wurden.
Das ist eine neue Aufbewahrungsgrenze.
Beam-Perspektive:
Sparse Memory Fine-Tuning ist eine der klarsten Demonstrationen bisher, dass LLMs zu „write-light, remember-heavy“-Systemen werden können, eine kritische Eigenschaft für selbstlernende Automatisierung, bei der ständige Voll-Updates nicht machbar sind.
Was an Fortwährendem Lernen noch schwierig ist
Trotz dieser Durchbrüche bleiben einige Probleme offen:
Bewertung über lange Horizonte
Das Messen sowohl des Lernens als auch des Vergessens über viele Updates hinweg ist noch immer schwierig.
Rauschige Echtzeit-Ströme
Unternehmensdaten enthalten Widersprüche, minderwertige Labels und konzeptionelle Drifts. Robustes fortwährendes Lernen ist noch nicht vollständig gelöst.
Sicherheit in immer lernenden Modellen
Wenn ein Modell immer lernt, benötigt es Regeln darüber, was nicht gelernt werden sollte. Sichere Aktualisierungen sind jetzt ein eigener Forschungsschwerpunkt.
Trotzdem ist die Richtung klar: adaptive Modelle werden zum Standard.
Warum Fortwährendes Lernen für Beam (und Enterprise AI) wichtig ist
Die Mission von Beam ist es, AI-Agenten zu schaffen, die aus Ihren Workflows sicher und kontinuierlich lernen.
Fortwährendes Lernen unterstützt dies auf drei direkte Arten:
1. Agenten leben in sich ändernden Prozessen
P2P, O2C, R2R, HR-Operationen, CX-Workflows, kein Unternehmensprozess bleibt still. Fortwährendes Lernen lässt Agenten absorbieren:
neue Regeln,
neue Ausnahmen,
neue Tools,
neue Sprache
ohne die alte Logik zu verlieren, die immer noch gilt.
2. Neu-Training von Grund auf skaliert nicht
Vollständige Neu-Trainings sind teuer, langsam und oft durch Datenaufbewahrungsbeschränkungen blockiert. Methoden des fortwährenden Lernens reduzieren die Aktualisierungskosten, während sie schützen, was bereits funktioniert.
3. Gedächtnis wird zum Unterscheidungsmerkmal
Die nächste Generation von Agentenplattformen wird an dauerhaftem Fortschritt gemessen, nicht an einmaligen Demos. Fortwährendes Lernen bringt Agenten diesem Ziel näher.
Wenn Sie einen Agenten möchten, der sich wie ein echtes Teammitglied verhält, das sich mit Erfahrung verbessert und nicht jedes Quartal zurückgesetzt wird, ist fortwährendes Lernen die Grundlage.
Wichtige Erkenntnisse
Das kontinuierliche Lernen bewegt sich von der Theorie zur Notwendigkeit.
Die klassischen Ansätze (Wiedergabe, Regularisierung, Isolation) haben den Werkzeugkasten geschaffen.
Aber was 2025 passiert, ist größer:
Googles Nested Learning rahmt das Lernen selbst als ein mehrstufiges System mit unterschiedlichen Aktualisierungsgeschwindigkeiten neu.
Metas Sparse Memory Fine-Tuning zeigt, dass selektives Schreiben in Speicherschichten das katastrophale Vergessen nahezu eliminieren kann.
Unterschiedliche Wege, dasselbe Ziel: Modelle, die in der Produktion weiterentwickeln, ohne zu vergessen, wer sie bereits sind.
Das ist nicht nur „KI-Fortschritt“.
Das ist das technische Rückgrat für selbstlernende Agenten und die Welt, auf die Beam hinarbeitet.
Häufig gestellte Fragen (FAQs)
Was ist kontinuierliches Lernen in der KI?
Kontinuierliches Lernen ist ein Trainingsparadigma, bei dem ein Modell im Laufe der Zeit aus neuen Daten lernt, ohne zuvor erlernte Fähigkeiten zu vergessen.
Was ist katastrophales Vergessen?
Katastrophales Vergessen tritt auf, wenn ein neuronales Netzwerk nach dem Lernen einer neuen Aufgabe an Leistung bei älteren Aufgaben verliert, aufgrund von Parameterinterferenz.
Wie unterscheidet sich kontinuierliches Lernen vom Fine-Tuning?
Fine-Tuning aktualisiert ein Modell einmal; kontinuierliches Lernen aktualisiert es wiederholt, während aktiv verhindert wird, dass es vergisst.
Ist RAG eine Form des kontinuierlichen Lernens?
Nein. RAG ruft frische Informationen zur Inferenzzeit ab, aktualisiert jedoch nicht dauerhaft das Wissen oder Verhalten des Modells.
Was sind die Haupttypen von Methoden des kontinuierlichen Lernens?
Wiedergabemethoden, Regularisierungsmethoden (wie EWC) und Parameterisolation/-erweiterungsansätze sind die drei Hauptfamilien.




