6 Min. Lesezeit
Die Zukunft der KI liegt nicht in größeren Modellen. Sie liegt in besserer Orchestrierung.


Kategorie
Die AI-Welt
Artikel teilen
Vor zwölf Monaten war die Antwort der KI-Branche auf jede Leistungsgrenze immer dieselbe: Das Modell muss größer werden. Mehr Parameter, mehr Trainingsdaten, mehr Rechenleistung. Jede Generation kostete mehr im Training, mehr im Betrieb und lieferte geringere Zuwächse bei den Benchmarks, die für Unternehmensanwendungen tatsächlich relevant sind.
Diese Entwicklung stößt an ihre Grenzen. Eine von Fachkollegen begutachtete PNAS-Studie aus dem Jahr 2025 ergab, dass Frontier-Modelle „kaum überzeugender sind als Modelle, die um eine Größenordnung oder mehr kleiner sind“, und dass weiteres Skalieren „die Leistung möglicherweise nicht um mehr als 1 Prozentpunkt steigern wird“. OpenAIs GPT-4.5, das am aggressivsten skalierte Modell des Unternehmens, brachte zwar qualitative Verbesserungen in subjektiven Bereichen, aber nichts Substanzielles in verifizierbaren Domänen wie Mathematik und Naturwissenschaften. Der weitaus größte Teil hochwertiger öffentlicher Textdaten ist bereits durch Trainingsläufe verbraucht, und zusätzliche Daten bringen nur noch abnehmende Erträge.
Die Skalierungsära ist nicht vorbei, aber ihre Grenzerträge schrumpfen. Und es entsteht eine Alternative, die die Gleichung grundlegend verändert.
Ein 7B-Modell, das GPT-5 übertroffen hat
Ein Team von Sakana AI veröffentlichte kürzlich auf der ICLR 2026 ein Paper, in dem es einen „Conductor“ vorstellt: ein Modell mit 7 Milliarden Parametern, das mittels Reinforcement Learning darauf trainiert wurde, GPT-5, Claude Sonnet 4, Gemini 2.5 Pro und mehrere Open-Source-Modelle zu koordinieren. Der Conductor löst Probleme nie selbst. Er zerlegt sie in Teilaufgaben, weist jede dem am besten geeigneten Modell zu, entwirft das Kommunikationsmuster zwischen ihnen und formuliert gezielt Prompt-Anweisungen für jeden Worker.
Die Ergebnisse waren beeindruckend. Der Conductor erreichte 87,5 % auf GPQA Diamond, während GPT-5 auf 82,3 % kam. Auf LiveCodeBench erzielte er 83,93 %, GPT-5 82,90 %. Beim AIME 2025, dem Benchmark für Mathewettbewerbe, erreichte er 93,3 % gegenüber 90,8 % bei GPT-5. Über jeden getesteten Benchmark hinweg, sowohl innerhalb als auch außerhalb der Domäne, übertraf der Orchestrator jedes einzelne Modell, das er steuerte.
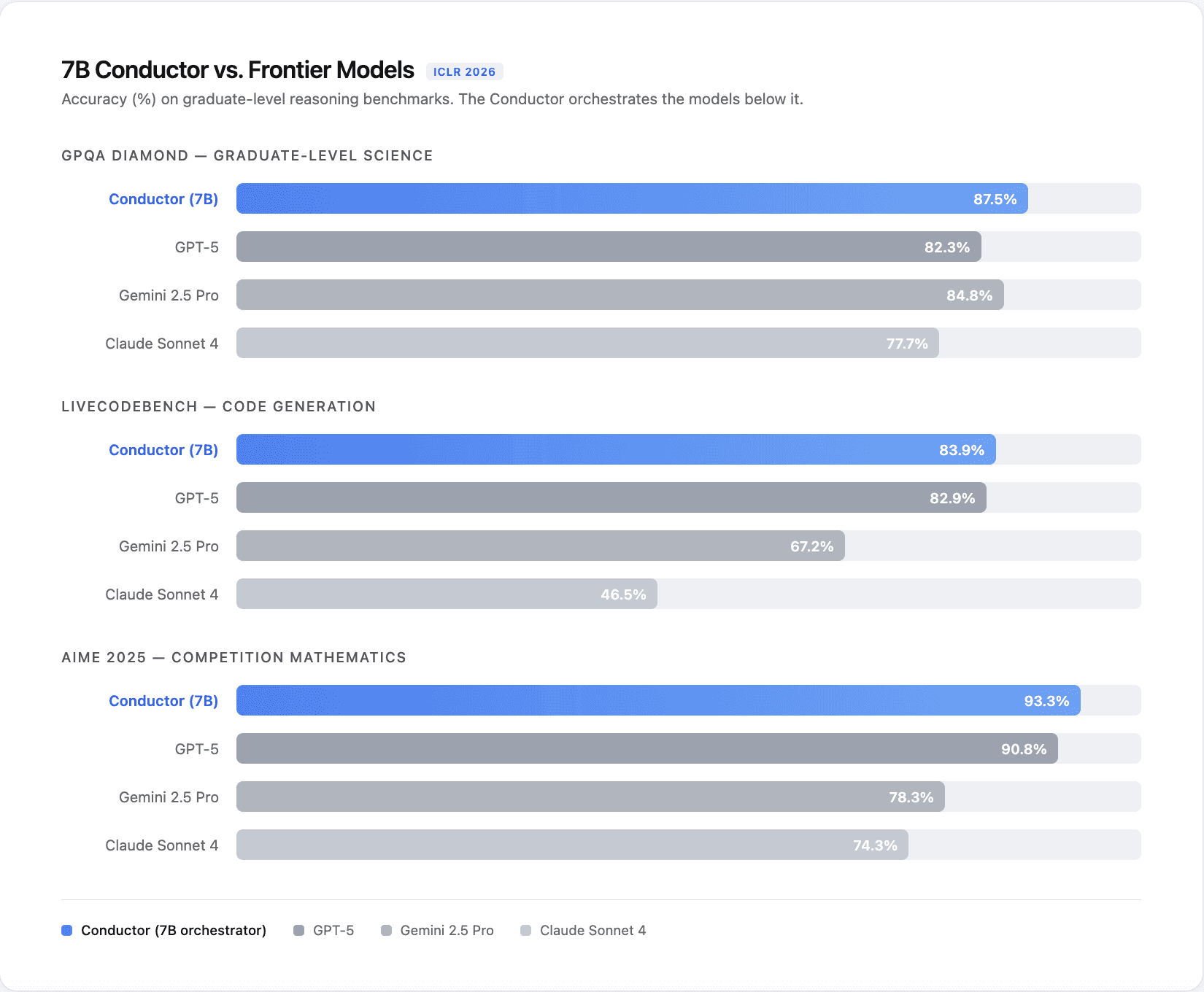
Ein etwa 200-mal kleineres Modell als die von ihm koordinierten erzeugte bessere Antworten, indem es deren komplementäre Stärken kombinierte, anstatt alles selbst wissen zu wollen. Das ist keine akademische Kuriosität. Es ist eine direkte Herausforderung an die Annahme, dass größer immer besser bedeutet.
Dieses Muster ist nicht isoliert. Das Mixture-of-Agents-Paper, das auf der NeurIPS 2024 angenommen wurde, zeigte, dass das Stapeln mehrerer LLMs in kollaborativen Runden eine Gewinnrate von 65,8 % auf AlpacaEval 2.0 erreichte, verglichen mit 57,5 % von GPT-4o — ein Plus von 8 Punkten allein durch Koordination. Separate Forschung zur effizienten Orchestrierung mehrerer Modelle zeigte eine Verbesserung der Genauigkeit um 21,7 %, eine Reduktion der Latenz um 33 % und eine Kostensenkung um 25 % gegenüber einer zufälligen Modellzuweisung. Die Evidenz verdichtet sich: Die Koordination vorhandener Modelle schlägt das Skalieren eines einzelnen Modells.
Warum Orchestrierung dort Wert schafft, wo Skalierung es nicht kann
Verschiedene Modelle sind in unterschiedlichen Dingen gut. Claude beherrscht nuanciertes Schlussfolgern und sorgfältige Analyse. Gemini glänzt bei multimodalen Aufgaben und breiter Wissensabfrage. GPT-5 führt bei bestimmten Coding-Benchmarks. Kein einzelnes Modell dominiert in allen Kategorien, und genau in dieser Lücke schafft Orchestrierung Wert.
Das Conductor-Paper hat etwas noch Interessanteres darüber offenbart, wie dieser Wert entsteht. Durch reines Reinforcement Learning entdeckte das Modell eigenständig Koordinationsstrategien, die menschliche Ingenieure typischerweise manuell entwerfen: Aufgabenzerlegung, Zuweisung von Spezialisten, gemeinsamer Reasoning-Kontext, Verifikationsrunden und iterative Verfeinerung. Es lernte, härteren Problemen mehr Agenten und mehr Schritte zuzuweisen, während es einfachere schlank hielt. Es lernte sogar Prompt-Engineering und schrieb bessere Anweisungen für GPT-5, als GPT-5 für sich selbst schreiben konnte.
Dieser letzte Punkt verdient Aufmerksamkeit. Das Modell, das ein Problem am besten löst, ist nicht zwangsläufig das Modell, das das Problem am besten definiert. Das sind zwei getrennte Fähigkeiten, und ihre Trennung führt zu besseren Ergebnissen. Nach diesem Prinzip funktionieren auch erfolgreiche Teams: Ein guter Manager, der weiß, wie man sinnvoll delegiert und Probleme präzise rahmt, kann aus einem Team mehr herausholen als jeder einzelne Contributor allein – ganz gleich, wie talentiert dieser ist.
Beams eigene Analyse des 19-Modell-Problems in der Enterprise-KI zeigte, dass Organisationen, die sich für alle Aufgaben auf ein einziges LLM verlassen, 40–85 % mehr bezahlen als jene, die intelligentes Routing nutzen. Eine einfache Lookup-Anfrage an ein Frontier-Modell zu senden, kostet etwa 30-mal mehr, als sie an ein kleineres Modell zu routen, das sie genauso gut verarbeitet. Multipliziert man das mit Tausenden täglicher Aufgaben, wird aus dem Kostenunterschied eine Position, die Finanzteams sehr wohl bemerken.
Unternehmen bewegen sich bereits in diese Richtung
Das ist kein theoretischer Wandel. Unternehmen stimmen mit ihren Budgets ab.
Gartner prognostiziert, dass 40 % der Enterprise-Anwendungen bis Ende 2026 aufgabenspezifische KI-Agenten einbetten werden, gegenüber weniger als 5 % im Jahr 2025. Das ist ein 8-facher Anstieg in nur einem Jahr. Gartner verzeichnete außerdem einen Anstieg der Anfragen zu Multi-Agenten-Systemen um 1.445 % von Q1 2024 bis Q2 2025. Eine LangChain-Umfrage unter 1.300 Praktikern ergab, dass 57,3 % bereits Agenten in der Produktion einsetzen, und Multi-Agenten-Architekturen wuchsen in weniger als vier Monaten um 327 %.
Nicht alle diese Agenten werden auf demselben Modell laufen. Sie benötigen Orchestrierungsmuster, die entscheiden, welches Modell welchen Schritt übernimmt, den Kontext zwischen Agenten verwalten und den Workflow an die jeweilige Aufgabe anpassen. JPMorgan Chase betreibt mehr als 450 KI-Use-Cases in der Produktion; sein COiN-System verarbeitet 12.000 Kreditverträge in Sekunden, indem unterschiedliche Dokumenttypen an unterschiedliche Modelle geroutet werden. Auf der Build 2025 stellte Microsoft Multi-Agent-Orchestrierung als Plattformfunktion erster Klasse vor, und der Einsatz von HCLTech löste Fälle 40 % schneller.
McKinsey schätzt, dass agentische KI jährlich einen Wert von 2,6 bis 4,4 Billionen US-Dollar schaffen könnte. Der Großteil dieses Werts entsteht nicht dadurch, dass ein einzelnes Modell intelligenter ist. Er entsteht durch Systeme, die mehrere Modelle, Tools und Datenquellen koordinieren, um End-to-End-Workflows abzuschließen, die kein einzelnes Modell allein bewältigen kann.
Die rekursive Möglichkeit
Der zukunftsweisendste Beitrag des Conductor-Papers ist die rekursive Orchestrierung. Indem der Conductor sich selbst als einen der Worker-Agenten aufrufen kann, entsteht eine Schleife, in der der Orchestrator seine eigene Koordinationsstrategie nach ersten Ergebnissen überarbeiten kann. Als GPT-5 bei BigCodeBench unerwartet schwach abschnitt, verschob der rekursive Conductor seinen Workflow automatisch zugunsten von Claude und Gemini bei nachfolgenden Versuchen und verbesserte sich ohne jegliches menschliches Eingreifen von 37,8 % auf 40,0 %.
Diese Art adaptiver, selbstkorrigierender Koordination unterscheidet ein produktives KI-System von einer Demo. Produktionsumgebungen sind unübersichtlich. Modelle verhalten sich je nach Eingabe unterschiedlich. Eine fest verdrahtete Orchestrierungspipeline bricht zusammen, wenn ihre Annahmen nicht mehr zutreffen. Eine gelernte, rekursive Orchestrierungsebene passt sich in Echtzeit an.
Für Teams, die heute agentische Workflows entwickeln, zeigt dies, wohin Investitionen in die Infrastruktur fließen sollten. Die Modelle werden sich weiterhin von selbst verbessern. Jedes Frontier-Labor investiert Milliarden, um genau das zu erreichen. Aber wie Sie diese Modelle kombinieren, routen und koordinieren, ist der Bereich, in dem sich der Wettbewerbsvorteil tatsächlich verstärkt – insbesondere, da die Fähigkeiten einzelner Modelle weiter aufeinander zulaufen.
Der eigentliche Engpass war nie die Modellgröße
Die KI-Branche hat die letzten drei Jahre in einem Parameterwettlauf verbracht. Größere Modelle, größere Cluster, größere Budgets. Die Evidenz legt inzwischen nahe, dass dieser Wettlauf ein Limit hat und dass die nächste Welle an Leistungsgewinnen aus besseren Systemen um bestehende Modelle herum entstehen wird, statt aus dem Neuaufbau noch größerer Modelle von Grund auf.
Ein 7B-Orchestrator, der GPT-5 übertrifft. Multi-Agenten-Systeme, die Frontier-Modelle bei Standard-Benchmarks um 8 Punkte schlagen. Unternehmen, die 40–85 % sparen, indem sie Aufgaben an das richtige Modell statt an das größte routen. Das Muster ist konsistent über Forschungslabore, Enterprise-Deployments und Produktionsökonomie hinweg.
Die Modelle werden zu Commodities. Die Orchestrierungsebene nicht. Und genau dort wird die Zukunft von KI-Performance, Kosteneffizienz und Unternehmenswert gerade aufgebaut.




