11 Min. Lesezeit
Wie Claude Fable 5 im Vergleich mit den Top 3 chinesischen KI-Modellen für Unternehmen abschneidet


Kategorie
KI-Agenten
Artikel teilen
Anthropic hat gerade Claude Fable 5 veröffentlicht und die Benchmarks sind beachtlich. 95 % bei SWE-bench Verified, Platz eins der GDPval-AA-Bestenliste, die längsten unbeaufsichtigten Agenten-Durchläufe, die je demonstriert wurden. Der Preis ist allerdings ebenfalls beachtlich: 50 $ pro Million Output-Token, der höchste Preis aller Modelle eines führenden Labors.
In den sechs Wochen vor dieser Veröffentlichung haben drei chinesische Labore Modelle auf den Markt gebracht, die in Coding-Benchmarks mit Fable 5 gleichziehen – und das zu einem Bruchteil der Kosten (bis zu ein Siebenundfünfzigstel). DeepSeek V4-Pro, Qwen3.7 Max und Kimi K2.6 lagen bei SWE-bench Verified alle innerhalb eines halben Punktes beieinander; vierzehn Punkte hinter Claude, aber preislich um zwei Größenordnungen darunter.
Für Unternehmensteams, die AI-Agenten im Produktivbetrieb einsetzen, ist dies keine Entscheidung mehr für ein einziges Modell. Im Folgenden: die tatsächlichen Zahlen aus der Primärquelle jedes Modells, die Berechnung für reale Workloads und ein Framework zur Auswahl des richtigen Modells für die jeweilige Aufgabe – einschließlich der Frage, wo das Spitzenmodell nach wie vor gewinnt und wo nicht.
Die vier Modelle in einer Übersicht
Bevor wir ins Detail gehen, die wichtigsten Zahlen aus der Primärquelle jedes Modells.
Drei Dinge fallen sofort auf. Die drei chinesischen Modelle liegen auf SWE-bench Verified innerhalb eines halben Punktes beieinander – ein Gleichstand im Benchmark. Jedes liegt vierzehn bis fünfzehn Punkte hinter Claude. Und die Output-Kosten erstrecken sich über fast zwei Größenordnungen, von siebenundachtzig Cent pro Million Token am günstigen Ende bis zu fünfzig Dollar an der Spitze.
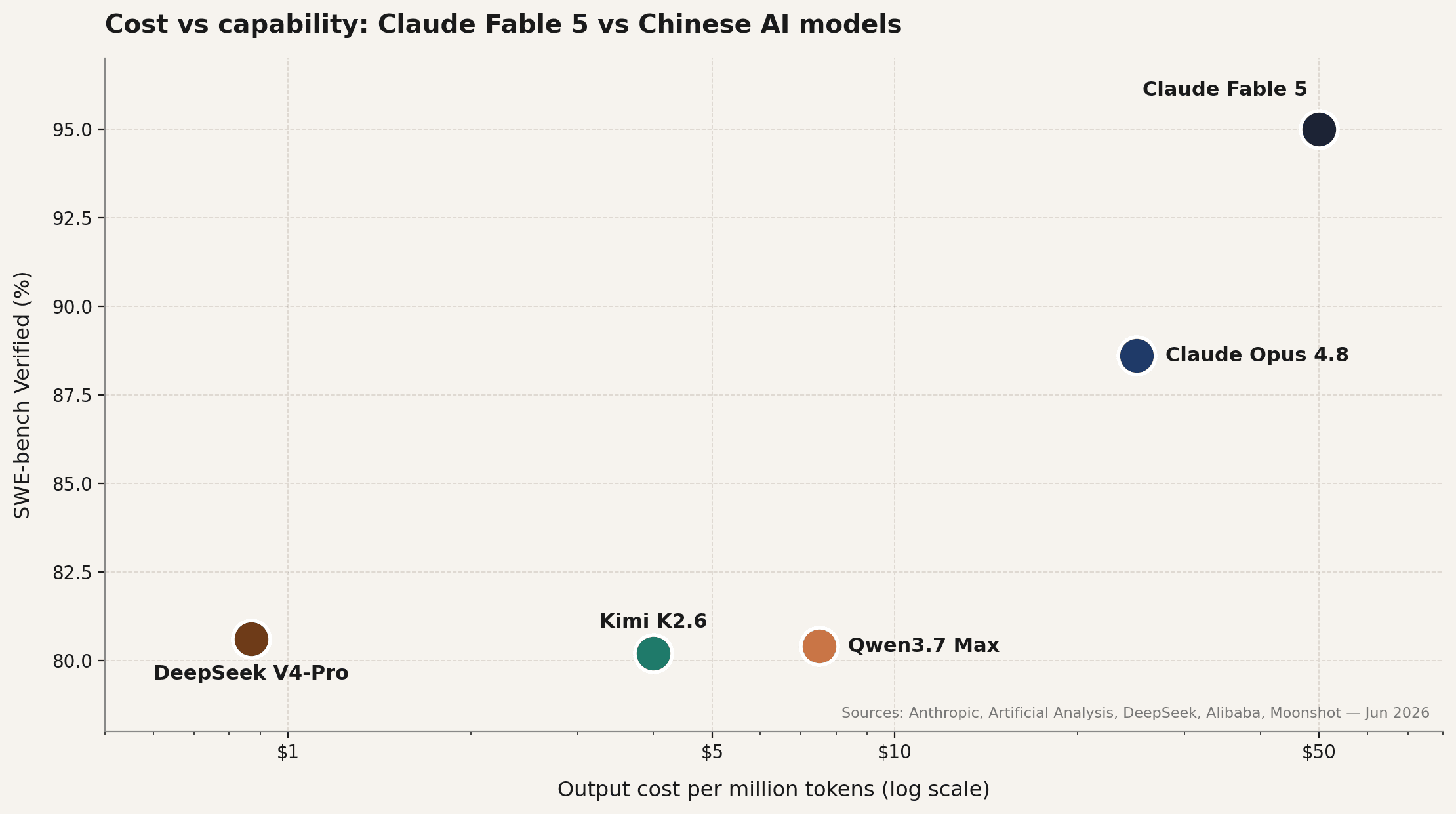
Was die Grafik zeigt, ist genau die Frage, um die es in diesem gesamten Artikel geht. Claude ist deutlich besser. Es ist aber auch deutlich teurer. Wann ist „deutlich besser“ also die Kosten tatsächlich wert?
Wie die Preislücke in tatsächlichen Zahlen aussieht
Token-Preise wirken abstrakt, bis man sie auf reale Workloads anwendet. Machen wir also das am Beispiel eines realen Workloads.
Stellen Sie sich einen typischen Enterprise-AI-Agenten vor. Er benötigt etwa 100.000 Token Kontext pro Aufruf: den System-Prompt, abgerufene Dokumente aus Ihrem ERP, den Konversationsstatus, die Tool-Definitionen. Er erzeugt etwa 5.000 Token Output pro Durchlauf. Sie führen ihn etwa 1.000 Mal am Tag im gesamten Unternehmen aus. Das entspricht in etwa der Token-Mathematik eines Agenten für die Kreditorenbuchhaltung, der einige tausend Rechnungen im Monat verarbeitet.
Hier ist ein Überblick über die Kosten für die vier Modelle für einen Monat.
Gleicher Workload, gleicher Aufbau des Agenten. Siebenunddreißigtausend Dollar bei Claude Fable 5. Eintausendvierhundert bei DeepSeek V4-Pro. Eine 26-fache Differenz.
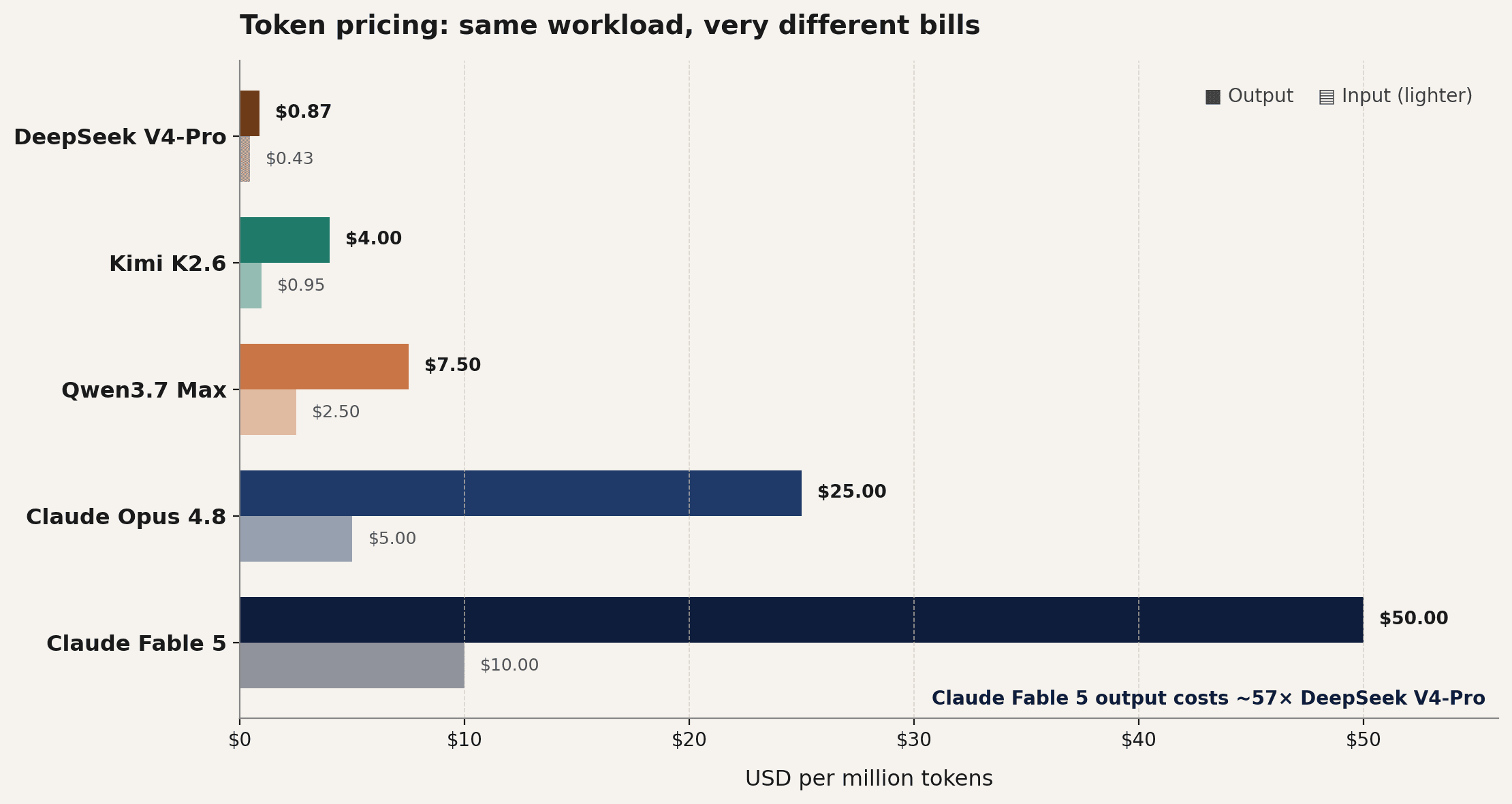
Multiplizieren Sie das nun mit der Anzahl der Agenten-Workloads, die Sie im nächsten Jahr produktiv schalten möchten. Jetzt verstehen Sie, warum sich CTOs plötzlich sehr für chinesische AI-Modelle interessieren.
Aber Sie sehen auch, warum dies keine Entscheidung für ein einziges Modell ist. Eine Rechnung von 37.500 $/Monat für Fable 5 kann ein Schnäppchen sein, wenn es das einzige Modell ist, das die Aufgabe bewältigen kann. Eine Rechnung von 1.435 $/Monat für DeepSeek kann eine Verschwendung sein, wenn der Agent in fünfzehn Prozent der Fälle versagt und Ihr Team die Einsparungen für das Beheben von Fehlern aufwenden muss.
Um zu wissen, was davon zutrifft, müssen Sie über den SWE-bench hinausblicken.
Wo das Benchmark-Gefälle tatsächlich eine Rolle spielt
SWE-bench Verified ist der am häufigsten zitierte Wert, misst aber eine ganz bestimmte Sache: Kann ein Modell Fehler in echten GitHub-Problemen beheben und diese mit einer Testsuite überprüfen. Das ist nützlich, aber nicht das, was produktive Agenten den ganzen Tag tun.
Die meisten Enterprise-Agenten verketten Tool-Aufrufe, rufen Daten aus einem System ab, transformieren etwas, übertragen es in ein anderes System, fangen Fehler ab, falls etwas fehlschlägt, und eskalieren, wenn sie keine Entscheidung treffen können. Die Benchmarks, auf die es bei dieser Arbeit ankommt, sind andere.
Wo Claude Fable 5 einen klaren Vorsprung behält:
GDPval-AA Elo von 1932, ein Maß für allgemeine Wissensarbeit im Unternehmen, bei der das Modell eine praxisnahe Aufgabe erhält und Prüfer diese bewerten. Opus 4.8 liegt bei 1890, GPT-5.5 bei 1769. Keines der drei chinesischen Modelle hat GDPval-Ergebnisse veröffentlicht, da sie an dem Benchmark nicht teilgenommen haben.
τ²-bench, das die Zuverlässigkeit der Tool-Nutzung in Telekommunikations-, Einzelhandels- und Luftfahrt-Workflows misst. Anthropic beschreibt Fable 5 als führend in allen drei Agenten-Evaluationen, hat in der Ankündigung jedoch keine spezifischen Ergebnisse veröffentlicht; mehrere Entwickler haben den Unterschied bei ungewohnten Tool-Ketten bereits in der ersten Woche nach der Veröffentlichung bestätigt.
Unbeaufsichtigte Durchläufe. Das Marketing-Versprechen von Anthropic lautet „Tage“ autonomer Arbeit. Die unabhängige Bestätigung: Entwickler posten Zeitrafferaufnahmen, in denen Fable über zehn Stunden lang ununterbrochen und ohne Eingriffe arbeitet. Je länger die Aufgabe, desto größer wird der Vorsprung von Claude – das Gegenteil dessen, was bei den meisten Modellen zu beobachten ist.
Wo chinesische Modelle mit Claude gleichziehen oder es übertreffen:
DeepSeek V4-Pro erreicht bei SWE-bench Verified gleichauf 80,6 %. Es ist stark beim Abrufen von Informationen aus langem Kontext – füttern Sie es mit einer Million Token, und es findet die relevante Textstelle.
Qwen3.7 Max führt bei Terminal-Bench 2.0-Terminus mit 69,7 % und liegt derzeit an der Spitze dieser Bestenliste. Es halluziniert in 22,9 % der Fälle; der zweitniedrigste Wert unter den Spitzenmodellen (Command A+ liegt mit 14,1 % niedriger), wobei ein Teil dieser Verbesserung darauf zurückzuführen ist, dass das Modell häufiger „Ich weiß es nicht“ sagt, anstatt mehr richtige Antworten zu liefern.
Kimi K2.6 erzielte in unabhängigen Tests von Artificial Analysis 96 % bei τ²-bench Telecom; das beste veröffentlichte Ergebnis in diesem Benchmark über alle Modelle hinweg. Seine Agent Swarm-Architektur skaliert auf bis zu 300 Sub-Agenten pro Aufgabe.
Das Muster zeigt: Claude gewinnt bei breit gefächerten Unternehmensaufgaben und lückenlosen, ungewohnten Workflows. Chinesische Modelle ziehen beim Coding gleich und übertreffen es bei spezifischen, eng abgegrenzten Aufgaben für Agenten, für die sie optimiert wurden.
Was niemand in den Modellvergleich einbezieht
Hier ist der Datenpunkt, der alles in ein neues Licht rücken sollte: Die meisten Enterprise-AI-Agenten-Piloten gehen nie produktiv.
Der Bericht „State of Agentic AI 2026“ von Anaconda + Forrester stellte fest, dass 88 % der Agenten-Piloten den Sprung in die Produktion nicht schaffen. Nur 12 % schaffen es vom Proof of Concept (POC) in den tatsächlichen Geschäftsbetrieb. Die Gründe, die Unternehmensteams dafür nennen, decken sich nicht mit den Schwerpunkten der meisten Modellvergleiche.
Lücken bei der Evaluierung (64 % der Teams). Sie können nicht messen, ob der Agent wunschgemäß funktioniert.
Hemmnisse bei der Governance (57 %). Sie können nicht ohne Audit-Trails, Freigaben und Compliance-Richtlinien produktiv gehen.
Zuverlässigkeit (51 %). Der Agent versagt bei ungewohnten Workflows.
Bemerkenswert ist, was nicht unter den Top 3 ist: die Modellwahl. Welches Modell Sie wählen, ist den Faktoren nachgelagert, die Agenten tatsächlich daran hindern, produktiv zu gehen.
Das bedeutet nicht, dass die Modellwahl irrelevant ist. Es bedeutet, dass die Modellwahl erst dann getroffen wird, wenn Sie Evaluierung und Governance geklärt haben. Und an diesem Punkt wählen Sie das Modell aus, das zum spezifischen Workload passt, und nicht das Modell mit dem höchsten einzelnen Benchmark.
Wo die einzelnen Modelle tatsächlich an ihre Grenzen stoßen
Sobald Sie sich für einen Workload entschieden haben, scheitern die einzelnen Modelle im Produktivbetrieb meist an folgenden Punkten.
Claude Fable 5 scheitert am Budget. Die Leistungsfähigkeit ist da. Die Kosten hindern Sie jedoch daran, das Modell für volumenstarke Aufgaben einzusetzen, die diese Leistung gar nicht benötigen. Die Sicherheitsvorkehrungen sind zudem restriktiver als bei früheren Claude-Versionen; Nutzer berichten von einer Herabstufung auf Opus bei so harmlosen Anfragen wie Ernährungsplanung oder einfacher Biologieforschung. Für die meisten Unternehmensaufgaben spielt das keine Rolle; bei Workflows, die Biowissenschaften, Sicherheitsforschung oder regulierte Inhalte betreffen, sollte die Fehlalarmquote beim Security-Routing jedoch vor dem produktiven Einsatz getestet werden.
DeepSeek V4-Pro ist das beste der drei Modelle bei der Informationssuche in langem Kontext und der Code-Ausführung, tut sich im Vergleich zu Claude jedoch bei komplexen, mehrstufigen Fehlerbehebungen schwer – wenn ein Tool-Aufruf in ungewohnten Workflows fehlschlägt, ist das Verhalten zur Fehlerbehebung bei V4 spürbar weniger zuverlässig. Die NIST-CAISI-Bewertung im Mai 2026 stellte einen Leistungsrückstand von etwa acht Monaten gegenüber der US-Spitzentechnologie fest. Dieser Rückstand ist real, schrumpft aber schnell.
Qwen3.7 Max bietet die stärksten Agenten-Demos in diesem Vergleich. Die internen Demos von Alibaba zeigen 35-stündige unbeaufsichtigte Durchläufe und 1.158 Tool-Aufrufe pro Aufgabe. Es ist jedoch nur als API über das Alibaba Cloud Model Studio verfügbar. Proprietäre Gewichte, gehostet in China. Für regulierte Branchen, die EU- oder US-Kundendaten verarbeiten, ist dies in der Regel unabhängig von der Leistungsfähigkeit ein Ausschlusskriterium. Alibaba ist mit diesem Release von der Open-Weights-Tradition von Qwen abgewichen und hat damit die Optionen für Unternehmen eingeschränkt, die ihre Infrastruktur rund um Qwen als offene Alternative zum Spitzenmodell aufgebaut hatten.
Kimi K2.6 hat das kleinere Kontextfenster: 256.000 Token im Vergleich zu 1 Mio. bei den anderen drei Modellen. Für dokumentenintensive Workflows in Unternehmen (Rechtsprüfung, Vertragsanalyse, Abgleich über mehrere Dokumente hinweg) ist das ein echtes Limit. Positiv zu vermerken ist, dass es sich um ein Open-Weights-Modell mit MIT-Lizenz handelt, das auf Ihrer eigenen Infrastruktur bereitgestellt werden kann. Das Ergebnis von 96 % bei τ²-bench ist real, wenn Ihr Workload aus Tool-Aufrufketten besteht.
Open Weights vs. gehostete APIs
Zwei der drei chinesischen Modelle sind Open Weights. DeepSeek V4-Pro wird unter der MIT-Lizenz vertrieben. Kimi K2.6 ist auf Hugging Face unter einer modifizierten MIT-Lizenz verfügbar. Beide können heruntergeladen, auf der eigenen Infrastruktur bereitgestellt, auditiert und mit null ausgehenden API-Aufrufen betrieben werden.
Das ist heute wichtiger denn je. Wenn Ihr Unternehmen europäische Kundendaten unter der DSGVO, US-Gesundheitsdaten unter HIPAA, Finanzdaten unter SOX oder lokale Bankdaten verarbeitet, ist die Übermittlung dieser Daten über eine in China gehostete API in der Regel nicht zulässig. Die gehostete DeepSeek-API, Qwen3.7 Max im Ganzen (da nur als API verfügbar) und der gehostete Kimi-Endpunkt fallen für regulierte Workflows weg.
Das Self-Hosting von DeepSeek V4-Pro oder Kimi K2.6 bleibt eine Option. Damit übernehmen Sie jedoch die Kosten für den Betrieb eines MoE-Inferenzmodells mit 1,6 Billionen Parametern auf eigener Hardware – was mit erheblichen Kosten und Engineering-Aufwand verbunden ist. Token-Preise spielen keine Rolle mehr, wenn Ihnen die Hardware selbst gehört.
Anthropic fällt für diese Kategorie von Käufern in eine andere Klasse. Proprietäre Gewichte, aber das Unternehmen veröffentlicht SOC 2 Type II-Audits, verfügt über dokumentierte Kontrollen zur Datenverarbeitung und hat namhafte Fortune-500-Kunden als Referenzen. Für Unternehmen mit Sicherheitsüberprüfungen, die Anbieter-Audits beinhalten, ist dieses Ungleichgewicht real; nicht unüberwindbar, aber real.
Ein verständliches Entscheidungs-Framework
Die obigen Berechnungen ergeben ein Framework, das sich bei den bisherigen Workflows bewährt hat.
Nutzen Sie Claude Fable 5, wenn:
Die Aufgabe lang, präzise spezifiziert und hochgradig risikobehaftet ist
Ein einziger Fehler mehr kostet als die gesamte Inferenz-Rechnung
Sie eine dokumentierte Compliance-Struktur für Unternehmen benötigen
Der Agent über Stunden oder Tage unbeaufsichtigt laufen muss
Beispiele: Klärung von Ausnahmefällen in der Kreditorenbuchhaltung, Schadensprüfung, Vertragsprüfung, Compliance-Überwachung
Nutzen Sie DeepSeek V4-Pro (selbstgehostet), wenn:
Die Aufgabe ein hohes Volumen hat und weniger risikoreich ist
Vorgaben zur Datensouveränität gehostete APIs ausschließen
Sie über die Infrastruktur verfügen, um Open-Weights-Inferenz lokal oder in Ihrer eigenen VPC zu betreiben
Beispiele: Dokumentenklassifizierung in großem Stil, interne Q&A über den Datenbestand des Unternehmens, interne Tools
Nutzen Sie Kimi K2.6 (selbstgehostet), wenn:
Die Aufgabe stark auf Tools ausgerichtet ist und kürzere Agenten-Ketten erfordert
Sie Open Weights benötigen und ein Context Window von 256K ausreicht
Beispiele: Triage im Kundenservice, Ticket-Routing, Automatisierung von Vertriebsprozessen
Nutzen Sie Qwen3.7 Max, wenn:
Die Arbeit explorativer Natur oder für F&E gedacht ist und keinen Kundenkontakt hat
Eine in China gehostete API mit proprietären Gewichten akzeptabel ist
Sie bereits die Alibaba Cloud nutzen
Beispiele: interne Experimente, Content-Erstellung, Prototyping mit unkritischen Daten
Es geht nicht darum, sich für ein einziges Modell zu entscheiden. Die meisten Implementierungen von Enterprise-Agenten im nächsten Jahr werden über mindestens zwei Modelle hinweg geroutet werden. Claude für die geschäftskritischen Pfade, günstigere Open-Weights- oder chinesische Modelle für volumenstarke Inferenz, während die Orchestrierungsschicht das Routing übernimmt.
Was das für Ihr Team bedeutet
Die Annahme von 2024 und 2025, es gebe „ein Modell für alles“, ist vorbei. Claude Fable 5 ist ein echter Sprung nach vorn, insbesondere für lange, unbeaufsichtigte Aufgaben. Aber bei den meisten Workflows in den meisten Unternehmen wird die Entscheidung für ein einziges Modell Sie das Fünf- bis Fünfundzwanzigfache dessen kosten, was Sie bei der Auswahl des jeweils passenden Modells pro Aufgabe zahlen würden.
Die Teams, die in diesem Jahr Agenten in die Produktion bringen, werden nicht diejenigen sein, die das beste Einzelmodell gewählt haben. Es werden diejenigen sein, die die Orchestrierungs-, Evaluierungs- und Governance-Schicht aufgebaut haben, mit der sie Modelle je nach Workload austauschen können, ohne den Agenten neu programmieren zu müssen. In dieser Schicht liegen die von Anaconda/Forrester identifizierten Haupthindernisse. Hier entscheiden sich Produktiv-Agenten entweder im echten Einsatz oder verschwinden stillschweigend von der Roadmap.
Bei Beam betreiben wir produktive AI-Agenten für Finanz- und Operations-Teams in Unternehmen (AP-Automatisierung, Kontenabgleich, Schadensbearbeitung, Beschaffungs-Workflows) auf dem Modell, das am besten zur Aufgabe passt. Das Modell ist nur ein Stellglied. Die Orchestrierung, der Audit-Trail, die Integration und die Fehlerbehandlung sind das, was es im Produktivbetrieb tatsächlich funktionieren lässt.
Sehen Sie selbst, wie Beam produktive AI-Agenten auf Claude, DeepSeek, Qwen oder einer beliebigen Kombination davon ausführt – mit einer Orchestrierungsschicht, die auch die nächste Modell-Veröffentlichung übersteht.




