7 Min. Lesezeit
5 Produktionsmetriken für KI-Agenten, die Ihrem Monitoring-Dashboard fehlen


Kategorie
KI-Agenten
Artikel teilen
Ein AI-Agent kann eine Verfügbarkeit von 99,9 % aufweisen und dennoch in der Hälfte der Fälle falsche Ergebnisse liefern. Das ist das grundlegende Problem bei der Überwachung von AI-Agenten im Vergleich zu traditioneller Software.
Infrastrukturmetriken wie Uptime, Latenz, Fehlerraten und Durchsatz zeigen Ihnen lediglich, ob der Agent läuft. Sie sagen Ihnen jedoch nicht, ob er gut läuft. Ein Schadenbearbeitungs-Agent, der jede Einreichung automatisch genehmigt, ist technisch gesehen betriebsbereit. Gleichzeitig verbrennt er jedoch Unmengen an Geld. Ein KYC-Verifizierungsagent, der 70 % der Anträge zur manuellen Überprüfung weiterleitet, wird zwar nie „ausfallen“, macht aber seinen Job nicht richtig.
Teams, die AI-Agenten in der Produktion einsetzen und über die Pilotphase hinaus skalieren, verfolgen andere Kennzahlen. Diese fünf sind diejenigen, die die meisten Teams nach ihrem ersten Vorfall im Live-Betrieb hinzufügen, wenn sie feststellen, dass reine Verfügbarkeit nicht ausreicht.
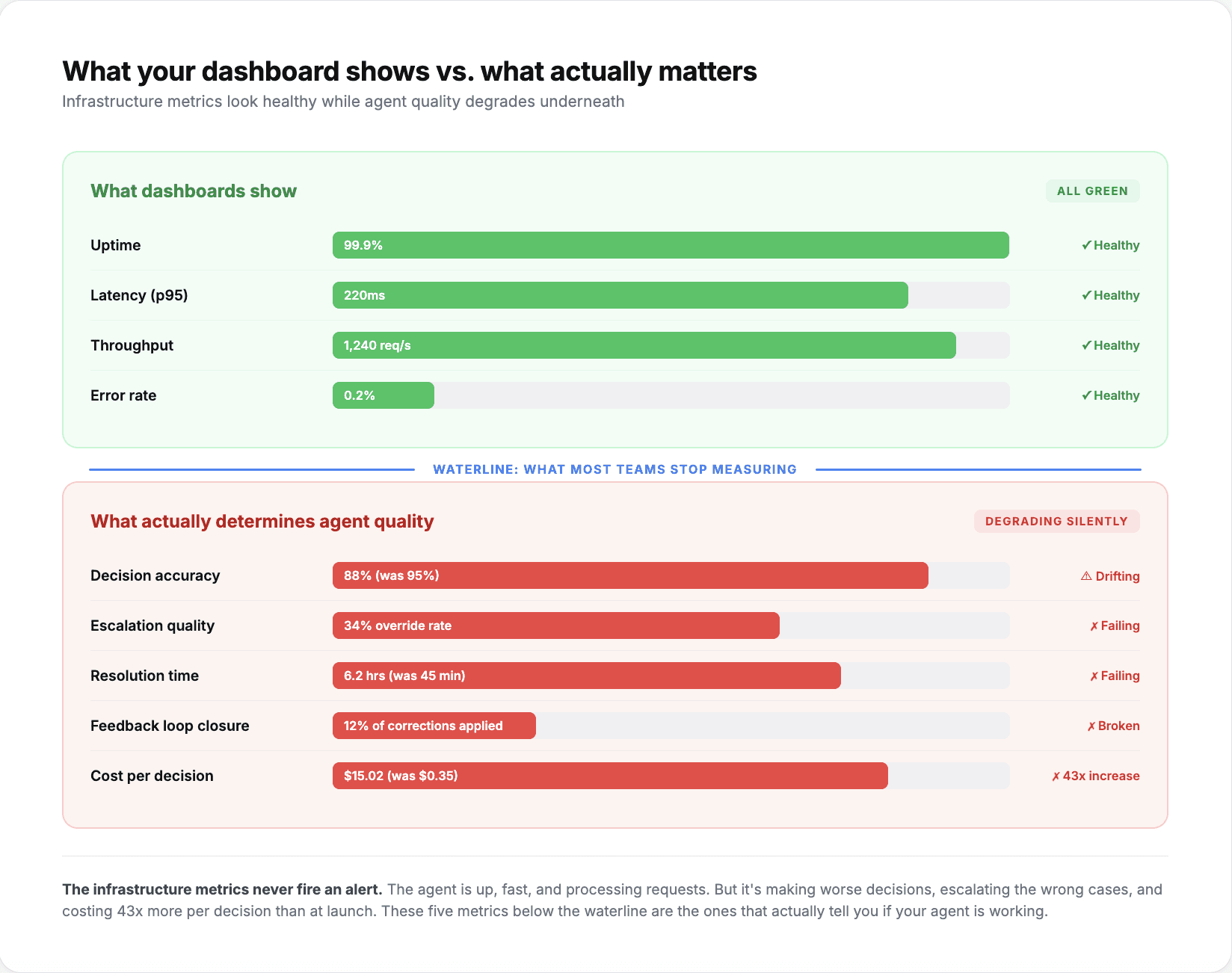
1. Entscheidungsgenauigkeit im Zeitverlauf (nicht nur beim Start)
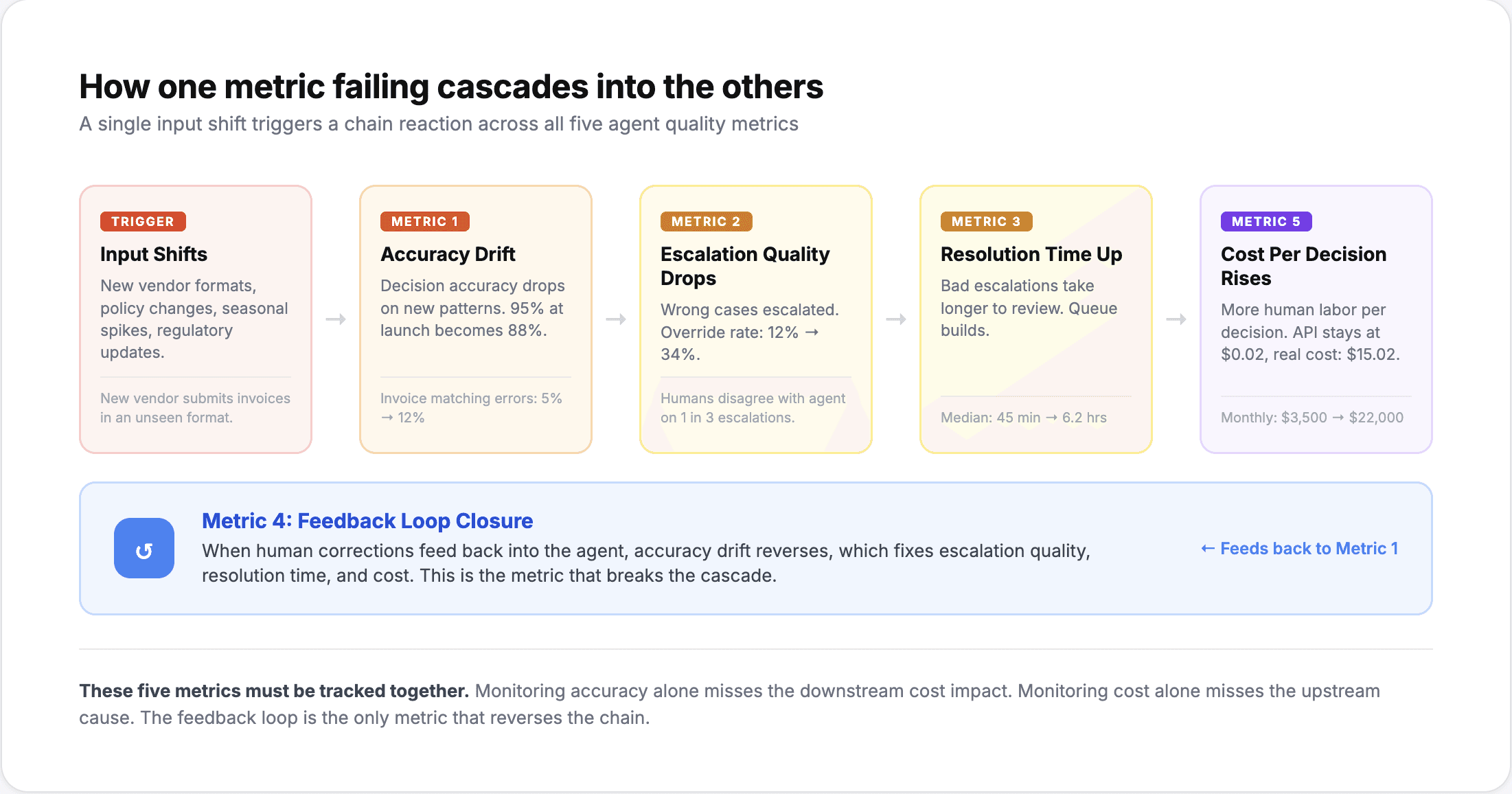
Die meisten Teams messen die Genauigkeit während der Testphase und beim Release. Nur wenige messen sie kontinuierlich in der Produktion. Dies ist die Metrik, mit der sich die häufigste Fehlerquelle aufdecken lässt: die schleichende Verschlechterung.
Ein Agent, der mit einer Genauigkeit von 95 % beim Abgleich von Rechnungen startet, liegt drei Monate später vielleicht nur noch bei 88 %. Nicht weil sich das Modell verschlechtert hat, sondern weil sich die Eingabedaten verändert haben. Ein neuer Lieferant hat Rechnungen in einem anderen Format eingereicht. Eine Richtlinienänderung hat einen neuen Genehmigungsworkflow eingeführt, für den der Agent nicht trainiert wurde. Saisonale Muster führten zu Transaktionsvolumina außerhalb des Trainingsbereichs.
Die Lösung ist einfach: Überprüfen Sie regelmäßig Stichproben der Entscheidungen des Agenten, vergleichen Sie diese mit einer von Menschen geprüften Datengrundlage (Ground Truth) und verfolgen Sie den Genauigkeitstrend. Plattformen mit selbstlernenden Fähigkeiten automatisieren diese Feedbackschleife. Eine europäische Neobank, die KYC-Agenten einsetzt, hält die Genauigkeit stabil bei 95,7 %, da sich das System kontinuierlich an neue Dokumententypen und regulatorische Änderungen anpasst, anstatt auf ein manuelles Modell-Update zu warten.
Was zu tracken ist: Wöchentliche Genauigkeitsrate pro Workflow. Alarmieren Sie, wenn die Genauigkeit um mehr als 3 Prozentpunkte unter den 30-Tage-Durchschnitt fällt. Segmentieren Sie nach Eingabetyp, wenn möglich, da eine aggregierte Genauigkeit einen Leistungsabfall in einzelnen Kategorien maskieren kann.
2. Eskalationsqualität (nicht nur die Eskalationsrate)
Die Eskalationsrate zeigt Ihnen, wie viele Entscheidungen der Agent an einen Menschen übergeben hat. Die Eskalationsqualität sagt Ihnen, ob diese Eskalationen berechtigt waren.
Es gibt zwei Arten von Fehlern. Zu geringe Eskalation bedeutet, dass der Agent Entscheidungen trifft, die er nicht treffen sollte. Zu häufige Eskalation bedeutet, dass der Agent Routineaufgaben an Menschen zurückgibt, was den Nutzen des Einsatzes zunichte macht. Die meisten Teams verfolgen die allgemeine Eskalationsrate (z. B. „unser Agent eskaliert 12 % der Schadensfälle“). Nur sehr wenige verfolgen, was nach der Eskalation passiert.
Die wirklich entscheidende Kennzahl ist die Korrekturquote durch Menschen bei eskalierten Entscheidungen. Wenn ein Agent einen Fall eskaliert und eine Ablehnung empfiehlt, und der Sachbearbeiter dies prüft und ebenfalls ablehnt, war die Eskalation korrekt. Wenn der Sachbearbeiter die Empfehlung jedoch in 40 % der Fälle revidiert, müssen die Eskalationskriterien des Agenten angepasst werden.
Enterprise-Implementierungen, die mehr als 10 Millionen Aufgaben verarbeiten, tracken dies auf Workflow-Ebene. Ein gut optimierter Agent sollte bei eskalierten Entscheidungen eine Korrekturquote von unter 15 % aufweisen. Alles über 25 % bedeutet, dass die Eskalationslogik neu trainiert werden muss und nicht nur die Schwellenwerte angepasst werden müssen.
Was zu tracken ist: Korrekturquote bei eskalierten Entscheidungen, segmentiert nach Workflow und Eskalationsgrund. Alarmieren Sie, wenn die Korrekturquote in einer einzelnen Eskalationskategorie 20 % überschreitet.
3. Bearbeitungszeit inklusive menschlicher Schritte (Time-to-Resolution)
Die End-to-End-Bearbeitungszeit ist die Metrik, die versteckte Engpässe im Workflow zwischen Mensch und Agent aufdeckt.
Teams messen die Verarbeitungszeit des Agenten oft isoliert: „Der Agent verarbeitet eine Rechnung in 4 Sekunden.“ Die tatsächliche Zeit von der Einreichung bis zur Erledigung kann jedoch 6 Stunden betragen, weil der Agent das Dokument eskaliert hat, die Eskalation 3 Stunden lang in einer Warteschlange lag, ein Mensch sie in 12 Minuten geprüft hat und die Benachrichtigung über den Abschluss aufgrund eines Batch-Prozesses weitere 2 Stunden dauerte.
Die Geschwindigkeit des Agenten ist irrelevant, wenn der Gesamtworkflow langsam ist. Die entscheidende Metrik ist die Zeit bis zur Lösung – gemessen von dem Moment an, in dem eine Aufgabe in das System gelangt, bis zu dem Moment, in dem sie abgeschlossen ist, einschließlich aller menschlichen Schritte, Wartezeiten in der Warteschlange und nachgelagerten Prozesse.
Versicherungsteams, die die Bearbeitungszeit von Schadensfällen von 60 Tagen auf 3 Tage verkürzt haben, haben dies nicht dadurch erreicht, dass sie den Agenten schneller gemacht haben. Sie erreichten dies durch die Neugestaltung des Workflows, sodass vom Agenten bearbeitete Fälle die manuelle Warteschlange komplett überspringen und eskalierte Fälle mit so viel Kontext ankommen, dass die menschliche Prüfung nur Minuten statt Stunden dauert.
Was zu tracken ist: Median der Bearbeitungszeit pro Workflow, aufgeteilt in: Antwortzeit des Agenten, Wartezeit, menschliche Prüfzeit und nachgelagerte Verarbeitungszeit. Alarmieren Sie, wenn der Median der Bearbeitungszeit im Wochenvergleich um mehr als 20 % steigt.
4. Abschlussrate der Feedbackschleife (Feedback Loop Closure Rate)
Wenn ein Mensch die Entscheidung eines Agenten korrigiert, verbessert diese Korrektur dann auch zukünftige Entscheidungen? Das ist die Metrik, die lernende Agenten von solchen unterscheidet, die Fehler immer wieder wiederholen.
In Systemen ohne Feedbackschleifen ist eine menschliche Korrektur eine einmalige Fehlerbehebung. Der Agent wird beim nächsten Mal bei ähnlichen Eingaben denselben Fehler machen. In Systemen mit Feedbackschleifen ist jede Korrektur ein Trainingssignal. Mit der Zeit sinkt die Fehlerrate bei diesem spezifischen Muster. Die Frage ist: Wie schnell?
Die Abschlussrate der Feedbackschleife misst den Prozentsatz an menschlichen Korrekturen, die innerhalb eines definierten Zeitfensters zu einer messbaren Verbesserung der Genauigkeit führen. Wenn ein Sachbearbeiter die Entscheidung eines Agenten bei einer bestimmten Art von Kfz-Schaden korrigiert und sich die Genauigkeit des Agenten bei dieser Schadensart innerhalb von 30 Tagen verbessert, ist die Schleife geschlossen.
Implementierungen mit aktiven Selbstlernmechanismen, wie die Neobank, die durch kontinuierliche Optimierung eine KYC-Genauigkeit von 95,7 % erreichte, weisen typischerweise eine Abschlussrate der Feedbackschleife von 70–85 % innerhalb von 30 Tagen auf. Systeme ohne aktives Lernen liegen bei 0 %, da die Korrekturen überhaupt nicht in das Modell zurückfließen. Teams, die sich auf vierteljährliche Modell-Updates verlassen, verzeichnen Abschlussraten von 20–30 %, mit monatelanger Verzögerung zwischen Korrektur und Verbesserung.
Was zu tracken ist: Prozentsatz der menschlichen Korrekturen, die innerhalb von 30 Tagen zu einer messbaren Verbesserung der Genauigkeit führen. Segmentieren Sie nach Korrekturtyp, um zu identifizieren, aus welchen Fehlermustern das System lernt und aus welchen nicht.
5. Kosten pro Entscheidung (nicht nur Kosten pro API-Aufruf)
Die irreführendste Metrik beim Einsatz von AI-Agenten sind die Kosten pro API-Aufruf. Sie zeigt Ihnen zwar die Infrastrukturkosten für den Betrieb des Modells, ignoriert aber alles andere.
Die Kosten pro Entscheidung beinhalten: die API- bzw. Inferenzkosten, die Kosten für den Datenabruf (aus ERP-Systemen, Datenbanken, APIs), die Kosten für die menschliche Überprüfung bei eskalierten Entscheidungen und die Fehlerbehebungskosten, wenn der Agent falsch liegt. Eine Entscheidung, die zwar nur 0,02 $ an API-Aufrufen kostet, aber in 30 % der Fälle eine manuelle Prüfung im Wert von 50 $ erfordert, kostet im Durchschnitt tatsächlich 15,02 $ pro Entscheidung.
Unternehmen, die Finanzprozesse in großem Stil betreiben, berichten, dass eine Reduzierung der menschlichen Eingriffe um 60–80 % im ersten Monat zu einer Senkung der Kosten pro Entscheidung um 70–90 % führt. Die Einsparungen stellen sich jedoch nur ein, wenn die Eskalationsraten niedrig und die Genauigkeit hoch bleiben. Ein günstigeres Modell, das häufiger eskaliert, kann pro Entscheidung teurer sein als ein teureres Modell, das autonomer agiert.
Was zu tracken ist: Vollständige Kosten pro Entscheidung, einschließlich menschlicher Arbeitskraft bei Eskalationen und Fehlerkorrekturen. Vergleichen Sie dies mit den Kosten pro Entscheidung vor dem Einsatz des Agenten für denselben Workflow. Alarmieren Sie, wenn die Kosten pro Entscheidung von Monat zu Monat steigen – das deutet in der Regel auf steigende Eskalationsraten oder eine Verschlechterung der Genauigkeit hin.
Aufbau einer Praxis zur Produktionsüberwachung
Diese fünf Kennzahlen haben ein gemeinsames Thema: Sie messen, ob der Agent seine Aufgabe korrekt erfüllt, und nicht nur, ob er läuft.
Die praktische Umsetzung besteht darin, diese Metriken als zweite Ebene über Ihr bestehendes Infrastruktur-Monitoring zu legen. Verfolgen Sie weiterhin Verfügbarkeit, Latenz und Fehlerraten – diese fangen Ausfälle und Performance-Einbußen ab. Fügen Sie dann die fünf oben genannten Metriken hinzu, um die Fehler zu erkennen, die das Infrastruktur-Monitoring nicht sieht.
Die meisten Enterprise-Agenten-Plattformen bieten Dashboards für Genauigkeitstracking, Eskalationsanalysen und Kostenrechnung. Wenn Ihre Plattform dies nicht bietet, besteht die einfachste Variante in einer wöchentlichen manuellen Überprüfung: Nehmen Sie eine Stichprobe von 50 Entscheidungen des Agenten, vergleichen Sie diese mit dem menschlichen Urteil, berechnen Sie die Korrekturquote für die Eskalationen dieser Woche und werten Sie die Ergebnisse im Zeitverlauf aus.
Die Teams, die eine solide Überwachung betreiben, sind diejenigen, die ihre Agenten auch nach dem ersten Quartal erfolgreich in der Produktion halten. Die Teams, die nur auf die Uptime achten, sind diejenigen, deren Agenten unbemerkt an Qualität verlieren, bis jemand die geschäftlichen Auswirkungen bemerkt – was meistens zu spät ist, um es ohne eine erneute Bereitstellung zu beheben.




