

Category
أتمتة العملاء
Share the article
توسيع منصة الذكاء الاصطناعي التي تعتمد بشكل كبير على الأتمتة ليس مجرد إضافة المزيد من الخوادم إلى المسألة. إنه يتعلق بإعادة التفكير في البنية التحتية، تحسين التنفيذ، وتصميم من أجل المرونة. في Beam AI، واجهنا تحديات نمو كبيرة في البداية - حيث كانت المهام الخلفية تستهلك موارد مفرطة، وواجهنا عقبات زادت من صعوبة التوسع.
اليوم، نقوم بتشغيل أكثر من 5000 مهمة في الدقيقة دون بذل أي مجهود. إليك كيف صممنا طريقنا للوصول إلى ذلك.
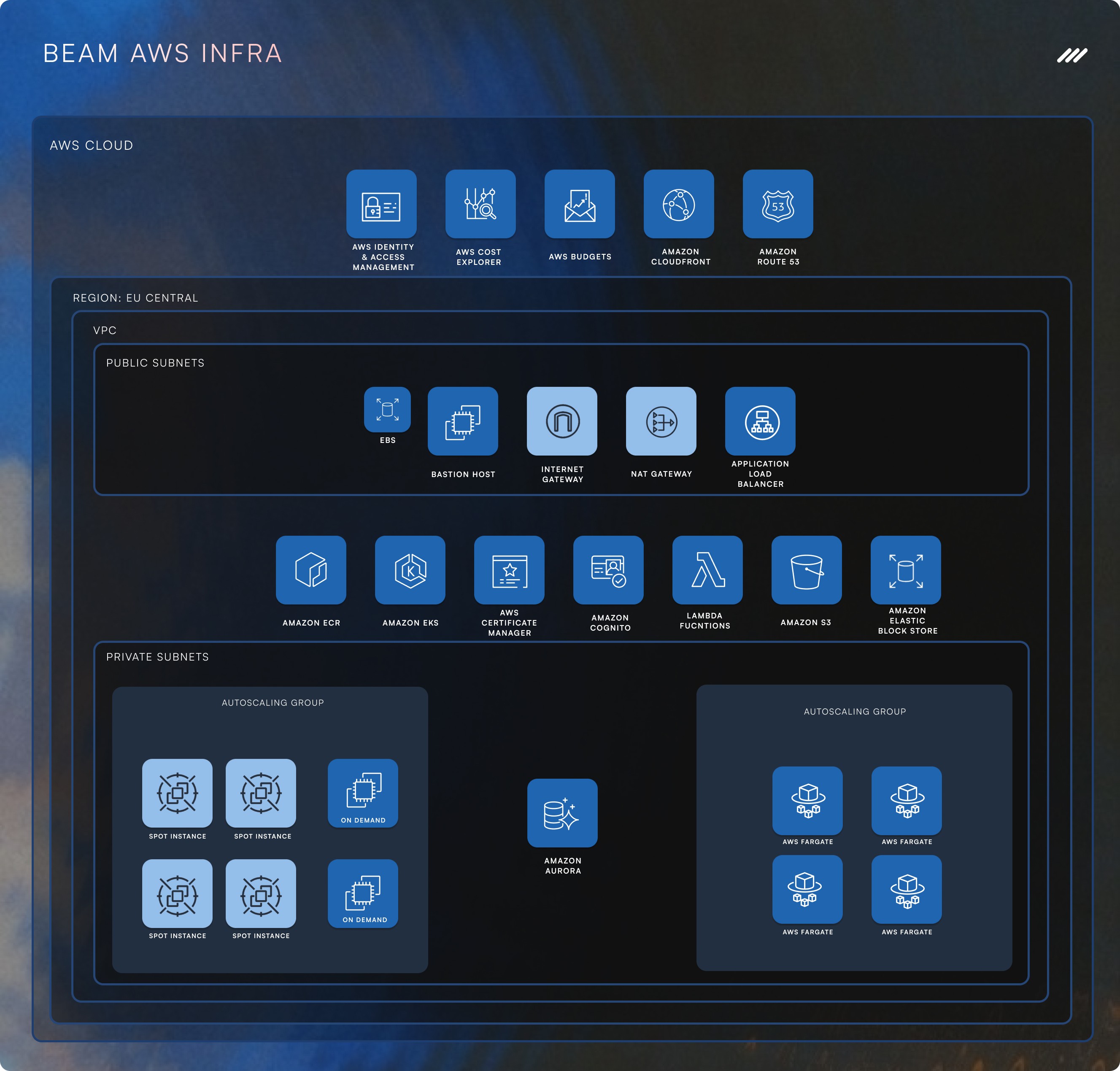
الصراعات المبكرة - لماذا لم يستطع نظامنا الأول التوسع
يعالج المهام الخلفية في Beam AI كميات هائلة من البيانات، تقوم بتشغيل مهام في الخلفية لأتمتة سير العمل وتنفيذ العمليات المدفوعة بالذكاء الاصطناعي. لكن في الأيام الأولى، كانت بنيتنا بعيدة عن أن تكون قابلة للتوسع:
كانت الخدمات تستهلك الموارد بشكل كبير، مما حد من عدد المهام التي يمكننا معالجتها.
اعتمدنا على مكالمات HTTP داخلية، مما أدى إلى عدم الكفاءة وإمكانية حدوث الأعطال.
كان نظامنا يفتقر إلى القدرة على تحمل الأخطاء، مما يعني أن خطأ واحداً يمكن أن يعطل سير عمل كامل.
كان من الواضح أننا بحاجة إلى تجديد جذري.
الخطوة 1: كوبيترنيتس: العمود الفقري لتوسعنا
كان الانتقال الكبير الأول هو الانتقال إلى كوبيترنيتس، والذي منحنا:
→ توافر عالي: ضمان بقاء الخدمات نشطة حتى لو فشلت المكونات الفردية.
→ عمليات نشر بدون انقطاع: يمكننا دفع التحديثات بدون تعطيل العمليات.
→ عزل الأعطال: لن تؤثر خدمة واحدة فاشلة على النظام بأكمله.
عن طريق تنسيق أحمال العمل الخاصة بنا باستخدام كوبيترنيتس، أزلنا نقطة اختناق رئيسية وأرسينا أساساً قابلاً للتوسع للنمو.
الخطوة 2: وسطاء الرسائل: استبدال المكالمات المتزامنة بالطابور الذكي
في الأصل، كانت خدمات Beam AI تتواصل عبر مكالمات HTTP مباشرة، مما أوجد اعتماديات ضيقة ونقاط فشل فردية. الحل؟ وسيط رسائل.
مع بنية قائمة على الرسائل، حصلنا على:
→ معالجة غير متزامنة: تستمع الخدمات للرسائل بدلاً من الانتظار للاستجابات المباشرة.
→ إدارة التحميل: يمكننا تحديد عدد المهام التي تعالجها كل خدمة في وقت واحد.
→ استرداد المهام: إذا تعطلت خدمة، فإنها تستأنف من حيث توقفت بمجرد إعادة التشغيل.
هذا التغيير حول كفاءتنا، مما سمح للخدمات بالتواصل دون تعطيل بعضها البعض أو التحميل الزائد.
الخطوة 3: تبديل نماذج زمن التشغيل: جعل الذكاء الاصطناعي أكثر كفاءة من حيث التكلفة
تعتبر نماذج الذكاء الاصطناعي قوية، لكن استخدام النماذج الكبيرة عشوائياً لكل مهمة يعد كابوسًا في التكلفة والأداء. لقد صممنا نظاماً لتبديل النماذج الديناميكي:
→ يختار LLMs بناءً على طول المستند وتعقيده.
→ استخدام نماذج مختلفة لأنواع مختلفة من المستندات لتحسين السرعة والدقة.
→ تقليل حدود المعدل وتكاليف API باستخدام النموذج المناسب للعمل المناسب.
هذا النهج لم يعمل فقط على تعزيز الأداء ولكنه جعل نظامنا أكثر فعالية من حيث التكلفة دون التضحية بالجودة.
الخطوة 4: تقسيم المهام لتحقيق أقصى قدر من الموثوقية
التوسع ليس فقط حول القيام بالمزيد، ولكن حول القيام بالمزيد مع الحفاظ على المرونة. لقد قمنا بتقسيم تنفيذ المهام الأحادية إلى خطوات مستقلة حتى:
→ يبلغ كل مرحلة عن التقدم إلى وسيط الرسائل.
→ يمكن للمهام الفاشلة أن تستأنف من الخطوة الأخيرة المكتملة بدلاً من البدء من جديد.
→ التنفيذ المتوازي ممكن، مما يحسن الكفاءة.
هذا أعطانا تحكمًا دقيقًا في سير العمل الآلي، مما جعل Beam AI أكثر موثوقية من أي وقت مضى.
الخطوة 5: تحسين قاعدة البيانات: الانتقال إلى PostgreSQL مع دعم المتجهات
معالجة كميات هائلة من البيانات المنظمة وغير المنظمة تتطلب إعادة التفكير في استراتيجيتنا التخزينية. في البداية، استخدمنا مزيجًا من قواعد بيانات المتجهات، ولكننا انتقلنا إلى PostgreSQL مع دعم المتجهات من أجل:
→ عمليات بحث واسترجاع أسرع لتضمينات نماذج الذكاء الاصطناعي.
→ تخزين مركزي، مما يقلل من تجزئة قاعدة البيانات.
→ فهرسة أفضل لسير العمل الآلي الواعي بالسياق.
جعلت هذه الخطوة من البنية التحتية لدينا أكثر بساطة دون التضحية بالأداء.
الخطوة 6: منفذ API مخصص: أتمتة المكالمات الخارجية للوكلاء
لتحسين كيفية تفاعل وكلائنا الرقميين مع وحدات API الخارجية، قمنا ببناء منفذ API مخصص يقوم بما يلي:
→ يعالج طلبات API بكفاءة دون تعطيل سير العمل.
→ يدير عمليات إعادة المحاولة والفشل لضمان الموثوقية.
→ يندمج بسلاسة في مجموعة الأتمتة الخاصة بنا.
هذا ضمن تفاعلات سلسة بين Beam AI والخدمات الخارجية، مما جعل الأتمتة لدينا أكثر سلاسة وقوة.

التأثير: من 50 مهمة إلى أكثر من 5,000 مهمة في الدقيقة
مع هذه التغييرات المعمارية، شهد Beam AI قفزة ضخمة في قابلية التوسع. انتقلنا من معالجة أقل من 50 مهمة في وقت واحد إلى التعامل مع أكثر من 5,000 مهمة في الدقيقة - زيادة بنسبة 100 ضعف في السعة.
LLMOps: السر وراء أتمتة الذكاء الاصطناعي القابلة للتوسع
يتطلب توسيع سير عمل الذكاء الاصطناعي أكثر من مجرد ترقية البنية التحتية، بل يتطلب أفضل ممارسات LLMOps لإدارة:
ضبط الأداء لتحقيق أفضل دقة وسرعة.
أطر العمل القابلة للتوسع التي تتعامل مع تزايد الطلب.
تقليل المخاطر من خلال الرصد، وخطط استعادة الكوارث، وأفضل ممارسات الأمن.
تحسين الكفاءة من خلال الأتمتة وتخصيص الموارد بذكاء.
في Beam AI، LLMOps موجود في صميم استراتيجيتنا للتوسع، مما يسمح لنا بإدارة سير العمل في الذكاء الاصطناعي بكفاءة، وبتكلفة فعالة، ودون تنازلات في الأداء.
الخلاصة: التوسع عملية مستمرة
التوسع ليس حدثًا لمرة واحدة، بل هو عملية مستمرة لتحديد نقاط الاختناق، وتحسين البنية التحتية، والاستفادة من التكنولوجيا المناسبة. من خلال اعتماد Kubernetes، ووسطاء الرسائل، والتبديل الديناميكي للنماذج، وقواعد البيانات المحسّنة، بنينا نظامًا يمكنه التعامل مع الأتمتة عالية الحجم بثبات وكفاءة.
في Beam AI، نحن نستمر في التطوير على بنيتنا للحفاظ على التقدم. إذا كنت تواجه تحديات توسع مشابهة، فإن الدرس المستفاد بسيط: صمم من أجل المرونة، أتمت بذكاء، وكن دائمًا مستعدًا للتكيف.




