1 دقيقة قراءة
ما هو التعلم المستمر؟ (ولماذا يقود وكلاء الذكاء الاصطناعي الذاتيون التعلم)


Category
أتمتة العملاء
Share the article
تبدو نماذج الذكاء الاصطناعي ذكية، حتى يتغير العالم.
يبدأ وكيل دعم العملاء في تقديم إجابات قديمة بعد تحديث المنتج.
يفوت روبوت سير العمل المالي قواعد السياسة الجديدة التي تم طرحها الشهر الماضي.
ينسى مساعد التوظيف قواعد التوظيف في الربع الماضي بمجرد أن يعلمها قواعد هذا الربع.
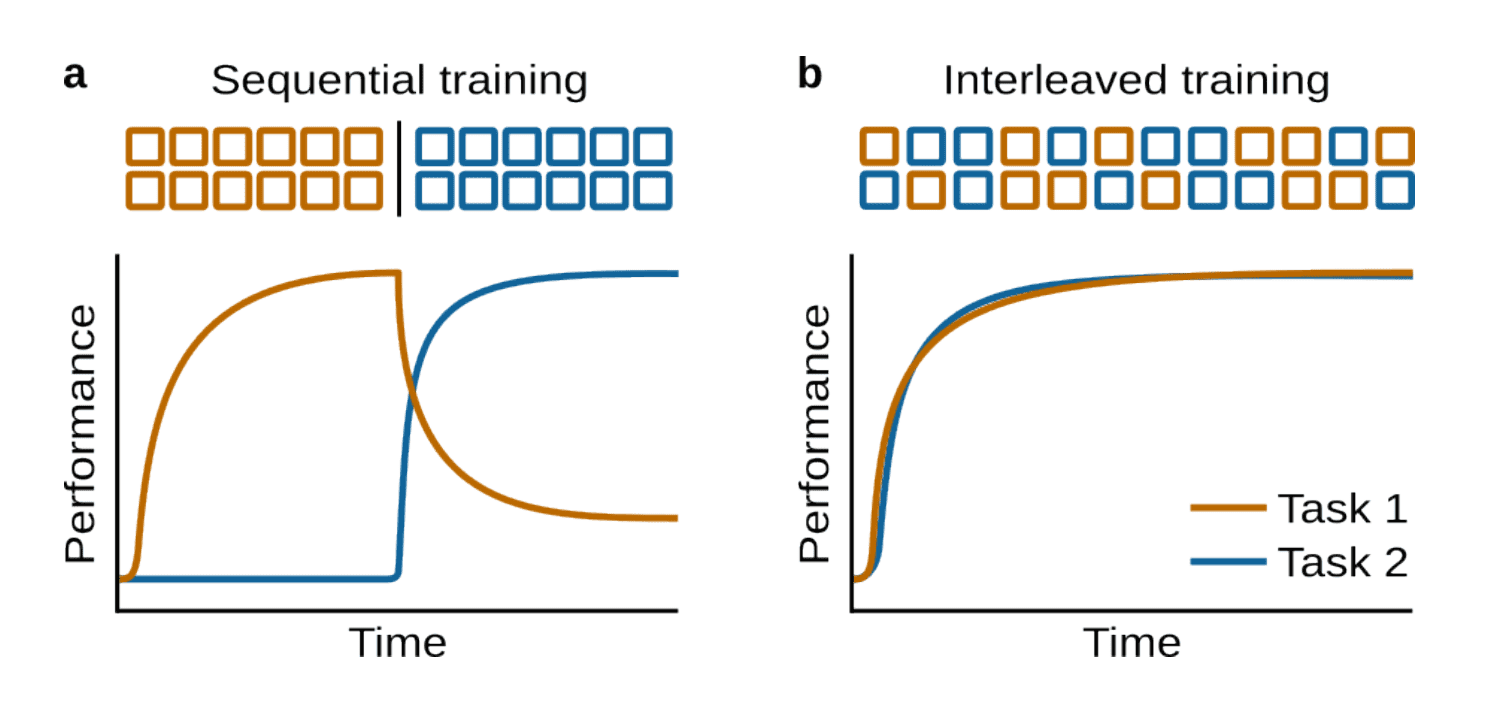
هذه ليست حالات استثنائية. إنها ما يحدث عندما يُعامل الذكاء الاصطناعي ككيان ثابت في عمل ديناميكي.
التعلم المستمر هو الانتقال بعيداً عن ذلك. إنها الفكرة التي تقول إن النماذج يجب أن تستمر في التعلم بعد النشر دون فقدان ما يعمل بالفعل. السؤال الكبير هو: هل يمكن للذكاء الاصطناعي إضافة معرفة جديدة دون محو المعرفة القديمة؟ يسمي الباحثون وضع الفشل النسيان الكارثي.
في Beam، هذه المشكلة محورية في رؤيتنا لـ وكلاء الذكاء الاصطناعي الذاتي التعلم، وكلاء يتحسنون بمرور الوقت مع تطور سير العمل والبيانات وقواعد العمل. التعلم المستمر هو واحد من أعمدة البحث التي تجعل ذلك ممكناً.
ما هو التعلم المستمر؟
التعلم المستمر (ويسمى أيضًا التعلم مدى الحياة أو التعلم التدريجي) هو عندما يقوم النموذج بتحديث معرفته خطوة بخطوة من بيانات جديدة ومتغيرة دون إعادة التدريب من البداية ودون نسيان المهارات القديمة.
تعريفه يتم من خلال شرطين:
بيانات غير ثابتة
يتغير توزيع البيانات بمرور الوقت. تظهر حالات جديدة. يتغير سلوك المستخدمين. تتطور السياسات.
تحديثات تدريجية
يتعلم النموذج في سلسلة من التحديثات بينما يظل قابلًا للاستخدام.
بمعنى آخر، التعلم المستمر هو التعلم في العالم الواقعي، وليس التعلم في مجموعة بيانات مجمدة مختبرية.
بالنسبة للذكاء الاصطناعي في المؤسسات، فهذا ليس اختياريًا. إنه البيئة.
لماذا تنسى النماذج؟ شرح النسيان الكارثي
إذا دربت شبكة عصبية على المهمة أ، ثم عدلتها على المهمة ب، غالبًا ما ينهار الأداء على المهمة أ. هذا ما يسمى النسيان الكارثي.
لماذا يحدث ذلك:
تخزن نفس المعايير المعرفة القديمة والجديدة.
عندما تقوم المهمة ب بتحديث الأوزان، تتحرك بعيدًا عن الأمثلية للمهمة أ.
التدريب المتسلسل يسبب تداخل بين المهام.
المصدر: توضيح النسيان الكارثي، ورقة “التعلم المستمر والنسيان الكارثي”
مثال من Beam:
تخيل وكيل Beam يتعامل مع استثناءات الفواتير. قمت بضبطه على قواعد الموردين الجديدة للربع الرابع. فجأة، يبدأ في الفشل في القواعد القديمة التي لا تزال تنطبق على الموردين التاريخيين. "تعلم" الوكيل، ولكنه فقط من خلال تجاوز السلوك الحالي. هذا هو النسيان في تدفق العمل الإنتاجي.
لهذا السبب فإن "الضبط مرة أخرى" ليس استراتيجية حقيقية للوكالات التي تعيش لفترة طويلة.
التعلم المستمر مقابل الضبط مقابل RAG (لماذا هذا مهم لنماذج اللغة الكبرى)
غالبًا ما يخلط الناس بين هذه الأمور، فلنفصلها بوضوح:
الضبط
يحدث تحديث للنموذج، ولكن ما لم يتم التحكم فيه، فإنه يخاطر بتجاوز المهارات القديمة. رائع للتكيف مع المجال بصورة فردية، محفوف بالمخاطر للتحديثات المستمرة.
يضيف معلومات جديدة في وقت الاستدلال عن طريق استرجاع المستندات. إنه قوي، ولكنه لا يغير السلوك بشكل دائم. لا يزال النموذج يمكنه ارتكاب نفس الأخطاء البنيوية بعد أسبوع.
التعلم المستمر
يضيف معرفة جديدة دائمة مع الحفاظ على المعرفة القديمة، مما يسمح للنموذج بأن يتطور بالفعل مع مرور الوقت.
خلاصة Beam:
يحتاج الوكلاء الذكيون الحديثون إلى كل من الاسترجاع والتحسين المستمر. يحافظ الاسترجاع على تحديث الإجابات. ويحافظ التعلم المستمر على تحديث السلوك.
التوازن بين الثبات والتكيف
كل نظام تعلم مستمر يعمل على تحسين قوتين:
التكيف: تعلم أشياء جديدة بسرعة.
الثبات: الحفاظ على الأشياء القديمة.
الكثير من التكيف → نسيان.
الكثير من الثبات → لا يمكن للنموذج التكيف.
لذا فإن التعلم المستمر هو تطور محكم: التعلم دون إعادة كتابة عقلك بنفسك.
إعدادات التعلم المستمر: القائم على المهام مقابل الحر
يقيم الباحثون التعلم المستمر في إعدادين رئيسيين:
التعلم المستمر القائم على المهام
تصل البيانات في كتل واضحة (المهمة 1 → المهمة 2 → المهمة 3)، ويعرف النموذج متى تتغير الحدود.
مفيد للبحث، أقل واقعية للإنتاج.
التعلم المستمر الحر
تتحول البيانات تدريجيًا دون حدود واضحة. يجب على النموذج اكتشاف متى يتغير العالم والتكيف بسلاسة.
صعب، ولكنه أقرب إلى تدفقات المؤسسات الحقيقية.
سياق Beam:
الوكلاء في المؤسسات عادة ما يكونون بلا مهام. لا تأتي تذاكر الموارد البشرية في مراحل نظيفة. تتغير سياسات الموردين باستمرار. تتطور نوايا العملاء بشكل غير متوقع. الطرق المستمرة في التعلم المستمر التي تعمل في بيئات بلا مهام هي التي ستهم في عمليات الانتشار الحقيقية لـ Beam.
الطرق الأساسية للتعلم المستمر (عدة الأدوات الكلاسيكية)
تندرج معظم الأساليب في ثلاث فئات:
1. الإعادة / التمرين
مزج البيانات القديمة مع البيانات الجديدة أثناء التدريب حتى لا ينحرف النموذج.
الإيجابيات: احتفاظ قوي.
السلبيات: تخزين البيانات القديمة يمكن أن يكون مكلفًا أو خطيرًا أو محدودًا.
2. التنظيم
تقدير الأوزان الهامة للمهام القديمة ومعاقبة التغييرات عليها. يعتبر تثبيت الأوزان المرن (EWC) المثال الأشهر.
الإيجابيات: لا حاجة لتخزين البيانات القديمة.
السلبيات: يمكن أن يبطئ التعلم على مدى العديد من التحديثات.
3. العزلة / التوسع المعلمي
تخصيص معايير منفصلة للمهام الجديدة (مثل المحولات، أكوام LoRA، توجيه الخبراء).
الإيجابيات: يتجنب التداخل.
السلبيات: يمكن أن تنمو النماذج مع الوقت، ويمكن أن يصبح التوجيه معقدًا.
تلك الأساليب مفيدة، لكنها لم تصمم للتعلم المستمر على نطاق نماذج اللغة الكبيرة في الإنتاج. لهذا السبب العمل الجديد من Google وMeta يجذب الانتباه.
التعلم المتعشي من Google: إعادة التفكير في كيفية تعلم النماذج باستمرار
قدمت Google Research التعلم المتعشي في مؤتمر NeurIPS 2025. الادعاء الكبير: لقد كنا نفصل بين البناء الأمثل والتحسين لفترة طويلة، وهذا الفصل يحد من التعلم المستمر.
الفكرة الأساسية
بدلاً من اعتبار النموذج كعملية تعلم واحدة، يعامل التعلم المتعشي النموذج كـ بنية من المشكلات متداخلة داخليًا، كل واحدة تعمل على نطاق زمني مختلف.
فكر في الأمر على النحو التالي:
الأجزاء التي تتغير بسرعة تتكيف مع البيانات الجديدة،
الأجزاء التي تتغير ببطء تحتفظ بالمعرفة طويلة الأمد،
والنظام يتعلم كيفية تحديث نفسه.
HOPE: نموذج دليل المفهوم
جمع Google التعلم المتعشي مع بناء جديد يسمى HOPE، الذي يجمع بين:
نموذج تسلسل ذاتي التعديل (يتعلم قاعدة تحديثه الخاصة)، و
نظام ذاكرة مستمر يتجاوز الفروق بين الذاكرة القصيرة والطويلة الأمد.
لماذا يهم التعلم المتعشي
إذا كان بإمكانه التوسع، فإنه يشير إلى مستقبل حيث لا تحتفظ نماذج اللغة الكبيرة فقط بالسياق الطويل في المحفزات - بل إنها تتعلم بنيويًا في طبقات، تستعيد المهارات القديمة مع إضافة الجديدة. هذا فتح كبير لوكلاء دائمين.
عدسة Beam:
يتماشى التعلم المتعشي مع الاتجاه الذي تتحرك فيه Beam: وكلاء يقومون بالتحديث بأمان على مستويات متعددة، من سياق تدفق العمل قصير الأمد إلى المعرفة الإجرائية طويلة الأمد، دون الحاجة إلى إعادة تعيين كاملة للنموذج.
التعلم الدقيق بالذاكرة الموزعة من Meta: تعلم أشياء جديدة عن طريق التحديث لأقل نسبة
تناول ورقة Meta FAIR في أكتوبر 2025، "التعلم المستمر عبر ضبط الذاكرة المتناثر" مشكلة النسيان من الاتجاه المعاكس: لا تقم بتحديث كل المعايير، قم بتحديث ذاكرة موزعة وذات صلة فقط.
الفكرة الأساسية
يحدث النسيان لأن المهام تشترك في نفس المعايير. لذا تقدم Meta طبقة ذاكرة تحتوي على العديد من "فتحات" الذاكرة. في كل تمرير أمامي، يتم تفعيل فقط جزء صغير.
عندما تصل معرفة جديدة، يقوم النموذج بتحديث فقط الفتحات الأكثر ارتباطًا بهذه المعرفة.
كيفية اختيار أي ذاكرة يجب تحديثها
يستخدمون درجة نمط TF-IDF:
TF: مدى تكرار تفعيل الفتحة بواسطة البيانات الجديدة.
IDF: مدى ندرة استخدامها أثناء ما قبل التدريب.
الفتحات التي تكون عالية TF، وعالية IDF "آمنة للتحديث،" لأنها ذات صلة بالمعلومات الجديدة ولكنها ليست أساسية للسلوك القديم.
النتائج في جملة واحدة
في تجارب التعلم المستمر للأسئلة والأجوبة:
الضبط الكامل تسبب في انخفاض حوالي 89٪ في الأداء الأصلي،
LoRA تسبب في انخفاض حوالي 71٪،
التعلم الدقيق للذاكرة الموزعة فقط حوالي 11٪ بينما لا يزال يتعلم حقائق جديدة.
هذا هو الأمام الجديد للاحتفاظ.
عدسة Beam:
التعلم الدقيق للذاكرة الموزعة هو واحد من أوضح العروض حتى الآن بأن نماذج اللغة الكبيرة يمكن أن تصبح أنظمة "كتابة خفيفة، واحتفاظ ثقيل،" وهي سمة حاسمة للأتمتة التعلم الذاتي حيث لا تكون التحديثات الكاملة الدائمة ممكنة.
ما زال صعبًا بشأن التعلم المستمر
حتى مع هذه الاختراقات، لا تزال بعض المشاكل غير محلولة:
التقييم عبر أفق طويل
قياس كل من التعلم والنسيان عبر العديد من التحديثات لا يزال صعبًا.
تدفقات البيانات الواقعية الصاخبة
تحتوي بيانات المؤسسات على تناقضات، وتسمية منخفضة الجودة، وانحراف المفاهيم. التعلم المستمر القوي لم يتم حله بالكامل.
الأمان في النماذج المتعلمة دائمًا
إذا كان النموذج يتعلم طوال الوقت، فإنه يحتاج إلى قواعد حول ما لا يجب تعلمه. الآن يتم التعامل مع التحديث الآمن كموضوع بحث منفصل.
لا تزال الاتجاهات واضحة: النماذج التكيفية أصبحت بمثابة الأساس.
لماذا يهم التعلم المستمر لـ Beam (والذكاء الاصطناعي للمؤسسات)
مهمة Beam هي صنع وكلاء ذكاء اصطناعي يتعلمون من تدفقات العمل الخاصة بك، بصورة آمنة ومستمرة.
يدعم التعلم المستمر ذلك بثلاث طرق مباشرة:
1. يعيش الوكلاء داخل عمليات متغيرة
سلسلة التوريد، التجارة المادية، تقارير للأرباح، عمليات الموارد البشرية، تدفقات خدمات العملاء، لا تبقى أي عملية مؤسسة ثابتة. يتيح التعلم المستمر للوكلاء امتصاص:
قواعد جديدة،
استثناءات جديدة،
أدوات جديدة،
لغة جديدة
دون فقدان المنطق القديم الذي لا يزال ينطبق.
2. إعادة التدريب من الصفر لا يمكن توسعها
العمليات التدريبية الكاملة مكلفة وبطيئة وغالبًا ما تعوقها قيود الاحتفاظ بالبيانات. أساليب التعلم المستمر تقلل من تكلفة التحديث بينما تحمي ما يعمل بالفعل.
3. تصبح الذاكرة هي المميز
سيتم تقييم الأجيال القادمة من منصات الوكلاء بناءً على التحسين المستمر، وليس على العروض الفردية. التعلم المستمر يقرب الوكلاء من تلك العلامة.
إذا كنت تريد وكيلاً يتصرف كعضو حقيقي في الفريق، يتطور مع الخبرة بدلاً من إعادة التعيين كل ربع سنة، فالتعلم المستمر هو الأساس.
الخلاصة النهائية
التعلم المستمر يتحرك من النظرية إلى الضرورة.
الأساليب الكلاسيكية (إعادة التشغيل، التنظيم، العزل) أنشأت مجموعة الأدوات.
لكن ما يحدث في 2025 هو أكبر:
تعلم جوجل المتداخل يعيد تأطير التعلم نفسه كنظام متعدد المستويات بسرعات تحديث مختلفة.
تحسين ذاكرة Meta المتفرقة يظهر أن الكتابة الانتقائية لطبقات الذاكرة يمكن أن تقضي تقريبًا على النسيان الكارثي.
مسارات مختلفة، نفس الوجهة: نماذج تتطور في الإنتاج دون أن تمحو من هي بالفعل.
هذا ليس مجرد "تقدم في الذكاء الاصطناعي."
هذا هو العمود الفقري التقني للوكيل الذاتي التعلم، والعالم الذي تبنيه Beam.
الأسئلة المتكررة
ما هو التعلم المستمر في الذكاء الاصطناعي؟
التعلم المستمر هو نموذج تدريب حيث يتعلم النموذج من البيانات الجديدة بمرور الوقت دون نسيان المهارات التي تم تعلمها سابقًا.
ما هو النسيان الكارثي؟
النسيان الكارثي هو عندما يفقد الشبكة العصبية الأداء في المهام القديمة بعد تعلم مهمة جديدة، بسبب تداخل المعلمات.
كيف يختلف التعلم المستمر عن التحسين؟
التنقيح يحدث مرة واحدة؛ التعلم المستمر يحدث باستمرار مع منع النسيان بنشاط.
هل RAG شكل من أشكال التعلم المستمر؟
لا. RAG يسترجع المعلومات الجديدة أثناء وقت الاستنتاج لكنه لا يحدّث المعرفة أو السلوك الخاص بالنموذج بشكل دائم.
ما هي الأنواع الرئيسية لطرق التعلم المستمر؟
طرق إعادة التشغيل، وطرق الانتظام (مثل EWC)، ومقاربة العزل/التوسيع المعلمات هي الأُسر الثلاثة الرئيسية.




