

Categoría
Automatización Agenética
Compartir artículo
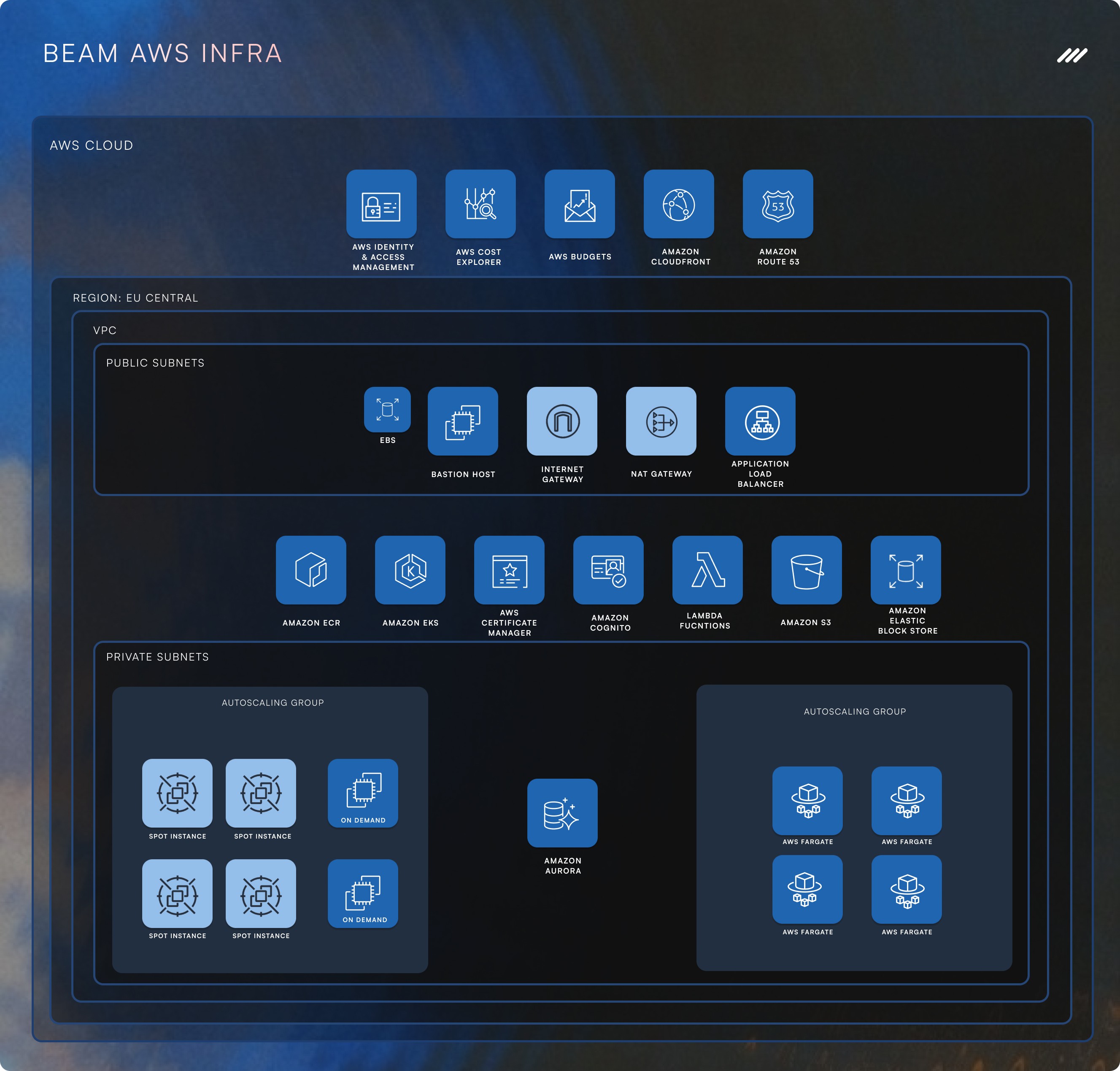
Escalar una plataforma de IA con gran uso de automatización nunca se trata solo de lanzar más servidores al problema. Se trata de repensar la infraestructura, optimizar la ejecución y diseñar para la resiliencia. En Beam AI, enfrentamos serios dolores de crecimiento desde el principio: nuestras tareas en segundo plano estaban consumiendo recursos excesivos y nos encontramos con cuellos de botella que hicieron que escalar fuera un desafío.
Hoy en día, ejecutamos más de 5,000 tareas por minuto sin sudar ni una gota. Así es como diseñamos nuestro camino hacia allí.
Las Primeras Dificultades: Por Qué Nuestro Primer Sistema No Podía Escalar
El backend de Beam AI procesa grandes cantidades de datos, ejecutando tareas en segundo plano que automatizan flujos de trabajo y realizan operaciones impulsadas por IA. Pero en los primeros días, nuestra arquitectura estaba lejos de ser escalable:
Los servicios eran voraces en recursos, limitando cuántas tareas podíamos procesar.
Dependíamos de llamadas HTTP internas, lo que llevaba a ineficiencias y posibles fallos.
Nuestro sistema carecía de tolerancia a fallos, lo que significaba que un fallo podía acabar con un flujo de trabajo completo.
Estaba claro que necesitábamos una renovación radical.
Paso 1: Kubernetes: La Columna Vertebral de Nuestra Escalabilidad
Nuestro primer cambio importante fue movernos a Kubernetes, lo que nos proporcionó:
→ Alta Disponibilidad: Asegurar que los servicios se mantuvieran operativos incluso si fallaban componentes individuales.
→ Despliegues sin Interrupciones: Podíamos aplicar actualizaciones sin interrumpir las operaciones.
→ Aislamiento de Fallos: Un único servicio que falla no podría impactar todo el sistema.
Orquestando nuestras cargas de trabajo con Kubernetes, eliminamos un gran cuello de botella y establecimos una base escalable para el crecimiento.
Paso 2: Gestores de Mensajes: Sustituyendo Llamadas Sincrónicas por Colas Inteligentes
Originalmente, los servicios de Beam AI se comunicaban a través de llamadas HTTP directas, lo que creaba dependencias estrictas y puntos únicos de fallo. ¿La solución? Un gestor de mensajes.
Con una arquitectura basada en mensajes, ganamos:
→ Procesamiento Asíncrono: Los servicios escuchan mensajes en lugar de esperar respuestas directas.
→ Gestión de Carga: Podemos limitar cuántas tareas procesa cada servicio a la vez.
→ Recuperación de Tareas: Si un servicio falla, retoma justo donde lo dejó una vez que se reinicia.
Este cambio transformó nuestra eficiencia, permitiendo que los servicios se comuniquen sin bloquearse entre sí ni sobrecargarse.
Paso 3: Cambio de Modelo en Tiempo de Ejecución: Haciendo la IA Más Rentable
Los modelos de IA son potentes, pero utilizar ciegamente modelos grandes para cada tarea es un infierno de costos y rendimiento. Diseñamos un sistema de cambio dinámico de modelos que:
→ Elige LLMs basándose en la longitud y complejidad del documento.
→ Utiliza diferentes modelos para diferentes tipos de documentos para optimizar la velocidad y la precisión.
→ Reduce los límites de tasa y costos de API al usar el modelo correcto para el trabajo adecuado.
Este enfoque no solo mejoró el rendimiento, sino que también hizo nuestro sistema más rentable sin sacrificar la calidad.
Paso 4: Descomposición de Tareas para Máxima Fiabilidad
Escalar no solo se trata de hacer más, se trata de hacer más mientras se mantiene resiliente. Desglosamos la ejecución de tareas monolíticas en pasos independientes, así que:
→ Cada etapa informa del progreso al intermediario de mensajes.
→ Las tareas fallidas pueden reiniciarse desde el último paso completado en lugar de comenzar de nuevo.
→ La ejecución paralela es posible, mejorando la eficiencia.
Esto nos dio un control detallado sobre los flujos de trabajo automatizados, haciendo Beam AI más confiable que nunca.
Paso 5: Optimización de Base de Datos: Cambio a PostgreSQL con Soporte de Vectores
Manejar grandes cantidades de datos estructurados y no estructurados requería repensar nuestra estrategia de almacenamiento. Inicialmente, usamos una mezcla de bases de datos vectoriales, pero hicimos la transición a PostgreSQL con soporte para vectores para:
→ Consultas y recuperación más rápidas de incrustaciones para modelos de inteligencia artificial.
→ Almacenamiento centralizado, reduciendo la fragmentación de la base de datos.
→ Mejor indexación para automatización sensible al contexto.
Este cambio simplificó nuestra arquitectura sin sacrificar el rendimiento.
Paso 6: Ejecutor de API Personalizado: Automatizando Llamadas Externas para Agentes
Para mejorar cómo nuestros agentes de IA interactúan con las APIs externas, construimos un ejecutor de API personalizado que:
→ Maneja solicitudes de API eficientemente sin bloquear los flujos de trabajo.
→ Gestiona reintentos y fallos para asegurar la fiabilidad.
→ Se integra perfectamente en nuestra pila de automatización.
Esto aseguró interacciones fluidas entre Beam AI y servicios externos, haciendo nuestra automatización más continua y resistente.

El Impacto: De 50 Tareas a 5,000+ Tareas por Minuto
Con estos cambios arquitectónicos, Beam AI experimentó un gran salto en escalabilidad. Pasamos de procesar menos de 50 tareas a la vez a manejar más de 5,000 tareas por minuto, un aumento de 100 veces en capacidad.
LLMOps: El Secreto para la Automatización Escalable de IA
Escalar flujos de trabajo respaldados por IA requiere más que solo mejoras en la infraestructura, demanda mejores prácticas de LLMOps para gestionar:
Optimización del rendimiento para precisión y velocidad óptimas.
Marcos de escalabilidad que manejan demanda creciente.
Reducción de riesgos mediante monitoreo, recuperación de desastres y mejores prácticas de seguridad.
Mejoras de eficiencia a través de la automatización y asignación inteligente de recursos.
En Beam AI, LLMOps está en el núcleo de nuestra estrategia de escalado, lo que nos permite manejar flujos de trabajo de IA de manera eficiente, rentable y sin sacrificios en el rendimiento.
La Conclusión: Escalar es un Proceso Continuo
Escalar no es un evento único, es un proceso continuo de identificación de cuellos de botella, optimización de infraestructura y aprovechamiento de las tecnologías adecuadas. Al adoptar Kubernetes, intermediarios de mensajes, cambio dinámico de modelos, y bases de datos optimizadas, construimos un sistema que puede manejar automatización de alto volumen con estabilidad y eficiencia.
En Beam AI, estamos constantemente iterando en nuestra arquitectura para mantenernos a la vanguardia. Si estás enfrentando retos de escalado similares, la conclusión clave es simple: Diseña para la resiliencia, automatiza inteligentemente y siempre está listo para adaptarte.




