1 min leer
¿Qué es el Aprendizaje Continuo? (Y por qué impulsa a los agentes de IA autoaprendientes)


Category
Automatización Agenética
Share the article
Los modelos de IA parecen inteligentes, hasta que el mundo cambia.
Un agente de atención al cliente comienza a dar respuestas obsoletas después de una actualización del producto.
Un bot de flujo de trabajo financiero pasa por alto nuevas reglas de políticas implementadas el mes pasado.
Un asistente de reclutamiento olvida la pauta de contratación del trimestre pasado una vez que le enseñas la de este trimestre.
Estos no son casos aislados. Son lo que sucede cuando la IA se trata como un artefacto estático en un negocio dinámico.
El aprendizaje continuo es la evolución que rompe con esta idea. Es la noción de que los modelos deben seguir aprendiendo después de la implementación sin perder lo que ya funciona. La gran pregunta es: ¿puede la IA agregar nuevo conocimiento sin eliminar el conocimiento antiguo? Los investigadores llaman a este fallo olvido catastrófico.
En Beam, este problema es esencial para nuestra visión de agentes de IA autoaprendientes, agentes que mejoran con el tiempo a medida que los flujos de trabajo, los datos y las reglas empresariales evolucionan. El aprendizaje continuo es uno de los pilares de investigación que hace esto posible.
¿Qué es el aprendizaje continuo?
El aprendizaje continuo (también llamado aprendizaje vitalicio o aprendizaje incremental) es cuando un modelo actualiza su conocimiento paso a paso a partir de datos nuevos y cambiantes sin necesidad de entrenar de nuevo desde cero y sin olvidar habilidades anteriores.
Lo definen dos condiciones:
Datos no estacionarios
La distribución de los datos cambia con el tiempo. Aparecen nuevos casos especiales. El comportamiento del usuario cambia. Las políticas evolucionan.
Actualizaciones incrementales
El modelo aprende en una secuencia de actualizaciones mientras sigue siendo utilizable.
En otras palabras, el aprendizaje continuo es aprender en el mundo real, no aprender en un conjunto de datos de laboratorio congelado.
Para la inteligencia artificial empresarial, eso no es opcional. Es el entorno.
¿Por qué los modelos olvidan? Explicación del olvido catastrófico
Si entrenas una red neuronal en la tarea A y luego la ajustas en la tarea B, el rendimiento en la tarea A suele colapsar. Eso es olvido catastrófico.
Por qué sucede:
Los mismos parámetros almacenan conocimiento viejo y nuevo.
Cuando la tarea B actualiza los pesos, se alejan del óptimo para la tarea A.
El entrenamiento secuencial provoca interferencias entre tareas.
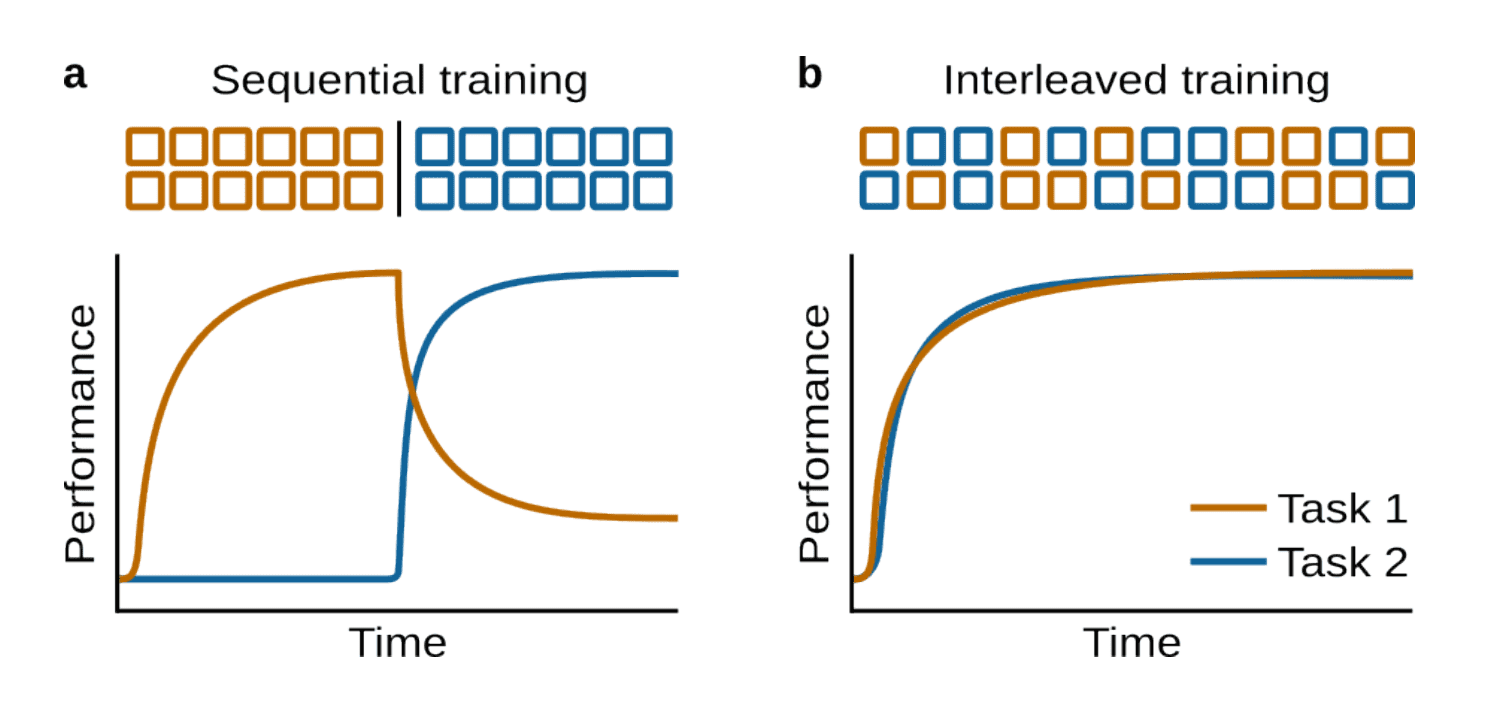
Fuente: Ilustración del olvido catastrófico, artículo “Aprendizaje Continuo y Olvido Catastrófico”
Ejemplo Beam:
Imagina un agente Beam manejando excepciones de facturas. Lo ajustas con reglas nuevas de proveedores para el cuarto trimestre. De repente, empieza a fallar con reglas anteriores que aún aplican a proveedores heredados. El agente “aprendió”, pero solo sobrescribiendo un comportamiento existente. Eso es olvido en un flujo de trabajo de producción.
Por eso “simplemente ajústalo de nuevo” no es una estrategia real para agentes de larga vida.
Aprendizaje continuo vs Ajuste fino vs RAG (Por qué esto importa para los LLM)
Las personas a menudo confunden estos términos, así que vamos a separarlos claramente:
Ajuste fino
Actualiza el modelo, pero a menos que se controle, corre el riesgo de sobrescribir habilidades viejas. Es excelente para adaptación temporal de dominio, pero arriesgado para actualizaciones continuas.
RAG (Generación aumentada por recuperación)
Añade información fresca en el momento de la inferencia recuperando documentos. Es poderoso, pero no cambia el comportamiento de forma permanente. Un modelo aún puede cometer los mismos errores estructurales una semana después.
Aprendizaje continuo
Añade nuevo conocimiento duradero mientras preserva el conocimiento antiguo, permitiendo que el modelo realmente evolucione con el tiempo.
Conclusión Beam:
Los agentes de IA modernos necesitan tanto recuperación como mejora continua. La recuperación mantiene las respuestas al día. El aprendizaje continuo mantiene el comportamiento actualizado.
El equilibrio entre estabilidad y plasticidad
Todo sistema de aprendizaje continuo está optimizando dos fuerzas:
Plasticidad: aprender cosas nuevas rápidamente.
Estabilidad: mantener cosas antiguas intactas.
Demasiada plasticidad → olvido.
Demasiada estabilidad → el modelo no puede adaptarse.
Así que el aprendizaje continuo es básicamente evolución controlada: aprender sin reescribir tu propio cerebro.
Configuraciones de aprendizaje continuo: basado en tareas vs sin tareas
Los investigadores evalúan el aprendizaje continuo en dos configuraciones principales:
Aprendizaje continuo basado en tareas
Los datos llegan en bloques claros (Tarea 1 → Tarea 2 → Tarea 3), y el modelo sabe cuándo cambian los límites.
Útil para investigación, menos realista para producción.
Aprendizaje continuo sin tareas
Los datos cambian gradualmente sin límites explícitos. El modelo debe detectar cuándo cambia el mundo y adaptarse sin problemas.
Más difícil, pero más cercano a los flujos empresariales reales.
Contexto Beam:
Los agentes empresariales casi siempre están sin tareas. Los tickets de RRHH no llegan en fases limpias. Las políticas de proveedores cambian continuamente. Las intenciones del cliente evolucionan de manera impredecible. Los métodos de aprendizaje continuo que funcionan en configuraciones sin tareas son los que importarán en los despliegues reales de Beam.
Métodos centrales de aprendizaje continuo (La clásica caja de herramientas)
La mayoría de los enfoques se dividen en tres familias:
1. Repetición / ensayo
Mezclar datos antiguos con datos nuevos durante el entrenamiento para que el modelo no se desvíe.
Ventajas: fuerte retención.
Desventajas: almacenar datos antiguos puede ser costoso, arriesgado o estar restringido.
2. Regularización
Estimar qué pesos fueron importantes para tareas antiguas y penalizar los cambios en ellos. Consolidación de Pesos Elásticos (EWC) es el ejemplo más conocido.
Ventajas: no hay necesidad de almacenar datos antiguos.
Desventajas: puede ralentizar el aprendizaje en muchas actualizaciones.
3. Aislamiento de parámetros / expansión
Asignar parámetros separados a nuevas tareas (adaptadores, pilas LoRA, enrutamiento experto).
Ventajas: evita la interferencia.
Desventajas: los modelos pueden crecer con el tiempo y el enrutamiento puede volverse complejo.
Estos métodos son útiles, pero no fueron diseñados para el aprendizaje continuo a escala LLM en producción. Por eso el nuevo trabajo de Google y Meta está recibiendo atención.
Aprendizaje anidado de Google: Repensando cómo los modelos aprenden de forma continua
Google Research introdujo el Aprendizaje Anidado en NeurIPS 2025. La gran afirmación: hemos estado separando arquitectura y optimización durante demasiado tiempo, y esa separación limita el aprendizaje continuo.
La idea central
En lugar de ver un modelo como un proceso de aprendizaje único, el Aprendizaje Anidado lo trata como una pila de problemas de aprendizaje anidados entre sí, cada uno operando a diferentes escalas de tiempo.
Piénsalo así:
las partes que cambian rápidamente se adaptan a los nuevos datos,
las partes que cambian lentamente preservan el conocimiento a largo plazo,
y el sistema aprende cómo actualizarse a sí mismo.
HOPE: el modelo de prueba de concepto
Google emparejó Aprendizaje Anidado con una nueva arquitectura llamada HOPE, que combina:
un modelo secuencial auto-modificable (aprende su propia regla de actualización), y
un sistema de memoria contínua que generaliza más allá de las divisiones de memoria a corto plazo vs largo plazo.
Por qué importa el Aprendizaje Anidado
Si esto escala, apunta a un futuro donde los LLM no solo mantienen un contexto largo en los prompts: aprenden estructuralmente en capas, recuperando habilidades antiguas mientras añaden nuevas. Eso es un desbloqueo importante para agentes siempre activos.
Visión Beam:
El Aprendizaje Anidado se alinea con la dirección que Beam está tomando: agentes que se actualizan de manera segura en múltiples niveles, desde el contexto de flujo de trabajo a corto plazo hasta el conocimiento procedimental a largo plazo, sin requerir reinicios completos del modelo.
Ajuste fino de memoria dispersa de Meta: Aprender cosas nuevas actualizando casi nada
El artículo de Meta FAIR de octubre de 2025, “Aprendizaje Continuo mediante Ajuste Fino de Memoria Dispersa,” aborda el problema del olvido desde la dirección opuesta: no actualices todos los parámetros, actualiza solo una memoria dispersa y relevante.
La intuición
El olvido ocurre porque las tareas comparten los mismos parámetros. Así que Meta introduce una capa de memoria con muchos “slots” de memoria. En cada pase hacia adelante, solo un conjunto pequeño se activa.
Cuando llega nuevo conocimiento, el modelo actualiza solo los slots más relacionados con ese conocimiento.
Cómo selecciona qué memoria actualizar
Usan una puntuación tipo TF-IDF:
TF: cuántas veces se activa un slot con los nuevos datos.
IDF: cuán raramente se usó durante el preentrenamiento.
Los slots que son altos en TF, altos en IDF son “seguros para actualizar”, porque son relevantes para la nueva información pero no esenciales para el comportamiento antiguo.
Los resultados en una línea
En sus experimentos de aprendizaje continuo para preguntas y respuestas:
el ajuste fino completo provocó una caída del ~89% en el rendimiento original,
LoRA causó una caída del ~71%,
el ajuste fino de memoria dispersa solo del ~11% mientras todavía aprende nuevos hechos.
Eso es una nueva frontera en retención.
Visión Beam:
El ajuste fino de memoria dispersa es una de las demostraciones más claras hasta ahora de que los LLM pueden convertirse en sistemas “ligeros para escribir, pesados para recordar”, un rasgo crítico para la automatización de autoaprendizaje donde las actualizaciones completas constantes no son factibles.
Lo que todavía es difícil acerca del aprendizaje continuo
Incluso con estos avances, algunos problemas permanecen abiertos:
Evaluación a largo plazo
Medir tanto el aprendizaje como el olvido a través de muchas actualizaciones sigue siendo difícil.
Flujos ruidosos del mundo real
Los datos empresariales contienen contradicciones, etiquetas de baja calidad y desviación de conceptos. El aprendizaje continuo robusto no está completamente resuelto.
Seguridad en modelos que siempre están aprendiendo
Si un modelo aprende para siempre, necesita reglas sobre qué no aprender. La actualización segura es un hilo de investigación separado ahora.
Aún así, como dirección, el cambio es claro: los modelos adaptativos se están convirtiendo en comunes.
Por qué el aprendizaje continuo importa para Beam (y la inteligencia artificial empresarial)
La misión de Beam es crear agentes de IA que aprendan de tus flujos de trabajo, de manera segura y continua.
El aprendizaje continuo apoya eso de tres maneras directas:
1. Los agentes viven dentro de procesos cambiantes
P2P, O2C, R2R, operaciones de RRHH, flujos de trabajo de CX, ningún proceso empresarial se queda quieto. El aprendizaje continuo permite a los agentes absorber:
nuevas reglas,
nuevas excepciones,
nuevas herramientas,
nuevo lenguaje
sin perder la lógica antigua que aún aplica.
2. El reentrenamiento desde cero no escala
Los reentrenamientos completos son costosos, lentos y a menudo bloqueados por restricciones de retención de datos. Los métodos de aprendizaje continuo reducen el costo de actualización mientras protegen lo que ya funciona.
3. La memoria se convierte en el diferenciador
La próxima generación de plataformas de agentes será juzgada por la mejora duradera, no por demostraciones de un solo tiro. El aprendizaje continuo acerca a los agentes al estándar.
Si quieres un agente que funcione como un miembro real del equipo, mejorando con la experiencia en lugar de reiniciando cada trimestre, el aprendizaje continuo es la base.
Conclusión final
El aprendizaje continuo está pasando de ser una teoría a una necesidad.
Los enfoques clásicos (repetición, regularización, aislamiento) crearon la caja de herramientas.
Pero lo que está sucediendo en 2025 es más grande:
Aprendizaje Anidado de Google redefine el aprendizaje como un sistema multinivel con diferentes velocidades de actualización.
Ajuste Fino de Memoria Escasa de Meta muestra que la escritura selectiva en las capas de memoria puede casi eliminar el olvido catastrófico.
Diversos caminos, mismo destino: modelos que evolucionan en producción sin borrar lo que ya son.
Eso no es solo “progreso de la IA”.
Esa es la columna vertebral técnica para agentes autoaprendientes, y el mundo hacia el cual Beam está construyendo.
Preguntas Frecuentes
¿Qué es el aprendizaje continuo en IA?
El aprendizaje continuo es un paradigma de entrenamiento donde un modelo aprende de nuevos datos a lo largo del tiempo sin olvidar habilidades previamente aprendidas.
¿Qué es el olvido catastrófico?
El olvido catastrófico ocurre cuando una red neuronal pierde rendimiento en tareas anteriores después de aprender una nueva tarea, debido a la interferencia de parámetros.
¿En qué se diferencia el aprendizaje continuo del ajuste fino?
El ajuste fino actualiza un modelo una vez; el aprendizaje continuo lo actualiza repetidamente mientras previene activamente el olvido.
¿Es RAG una forma de aprendizaje continuo?
No. RAG recupera información fresca en el tiempo de inferencia pero no actualiza permanentemente el conocimiento o comportamiento del modelo.
¿Cuáles son los principales tipos de métodos de aprendizaje continuo?
Los métodos de repetición, métodos de regularización (como EWC), y los enfoques de aislamiento/expansión de parámetros son las tres principales familias.




